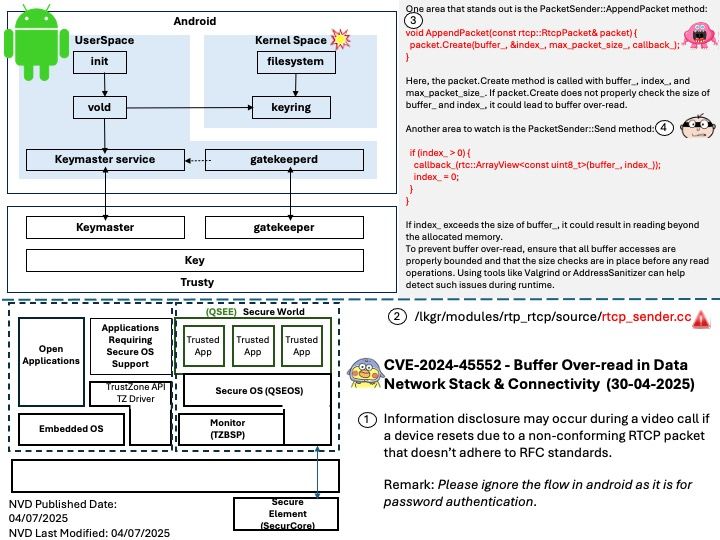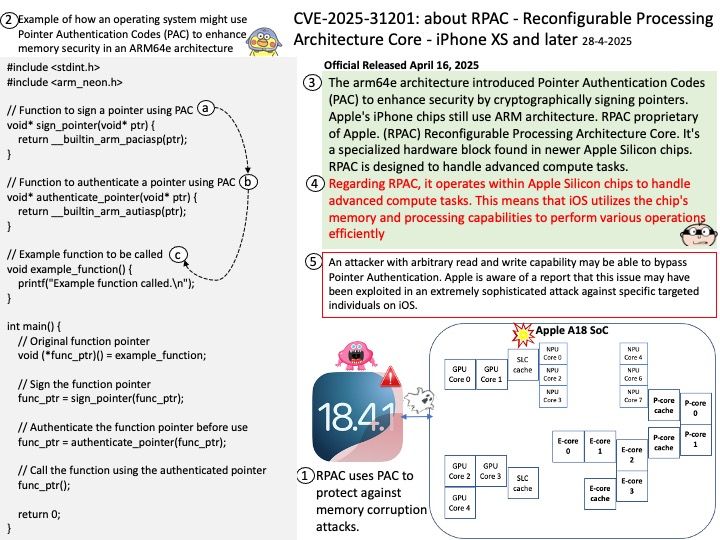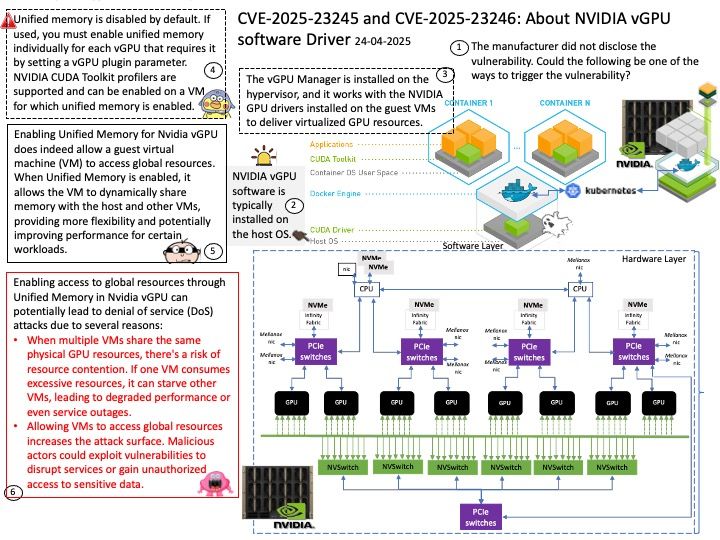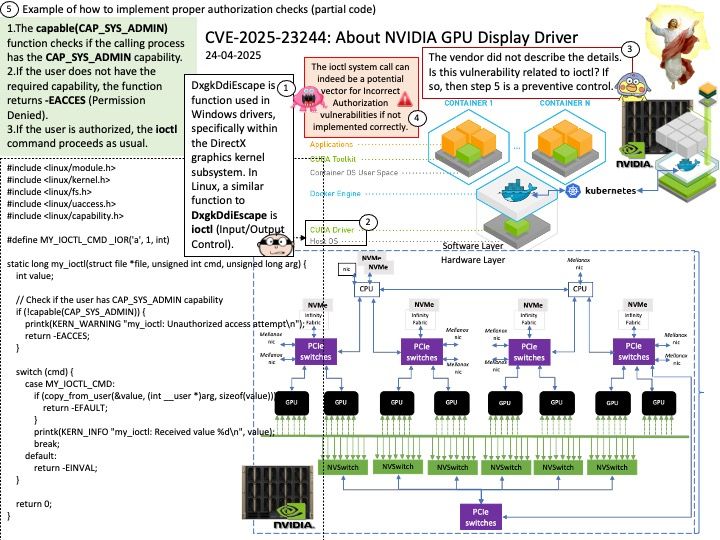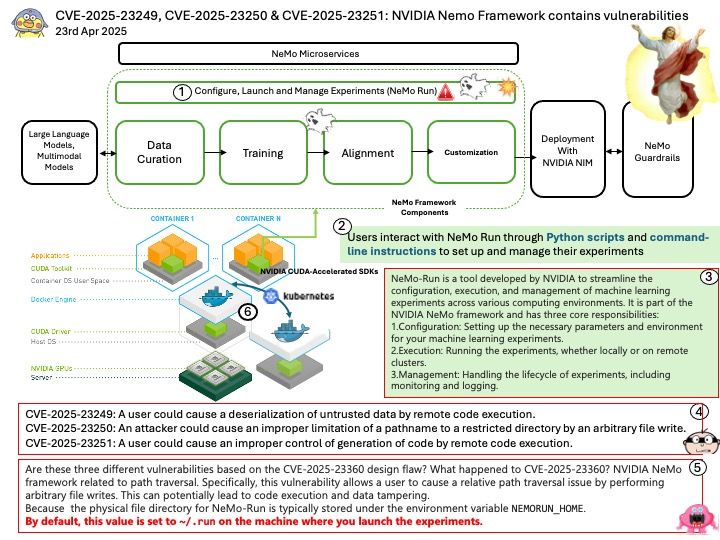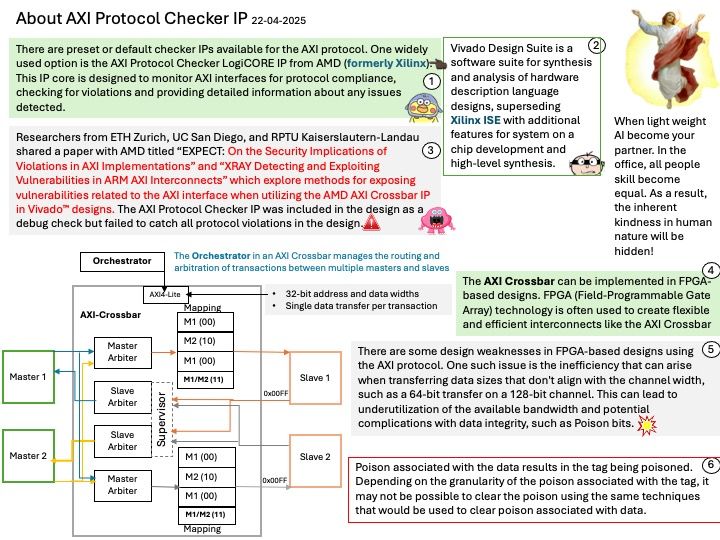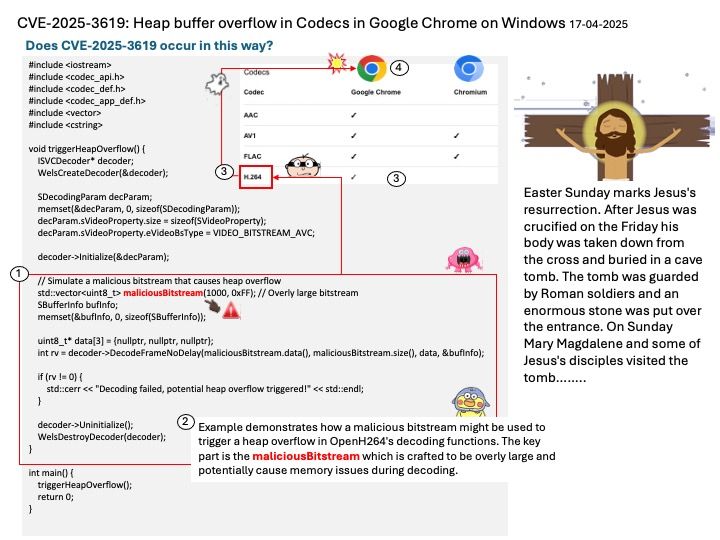
Preface: DeepSpeed MII, an open-source Python library developed by Microsoft, aims to make powerful model inference accessible, emphasizing high throughput, low latency, and cost efficiency. TensorRT LLM, an open-source framework from NVIDIA, is designed for optimizing and deploying large language models on NVIDIA GPUs.
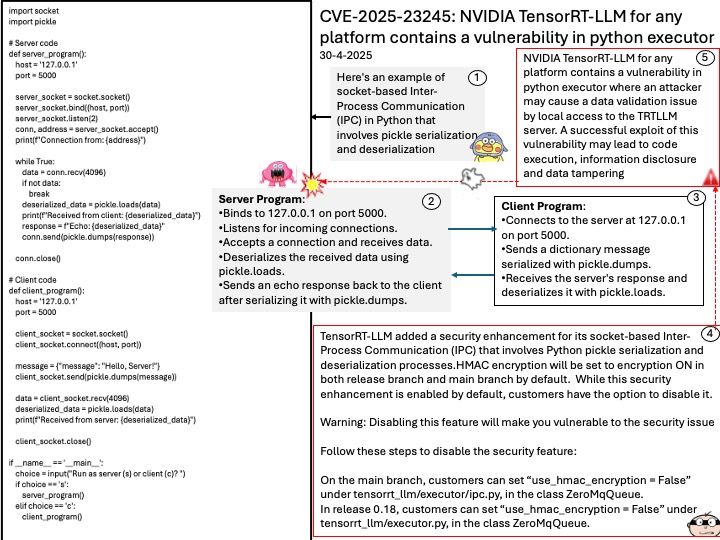
Background: TensorRT-LLM is a library developed by NVIDIA to optimize and run large language models (LLMs) efficiently on NVIDIA GPUs. It provides a Python API to define and manage these models, ensuring high performance during inference.
The Python Executor within TensorRT-LLM is a component that orchestrates the execution of inference tasks. It manages the scheduling and execution of requests, ensuring that the GPU resources are utilized efficiently. The Python Executor handles various tasks such as batching requests, managing model states, and coordinating with other components like the model engine and the scheduler.
Vulnerability details: NVIDIA TensorRT-LLM for any platform contains a vulnerability in python executor where an attacker may cause a data validation issue by local access to the TRTLLM server. A successful exploit of this vulnerability may lead to code execution, information disclosure and data tampering.
CWE-502: The product deserializes untrusted data without sufficiently ensuring that the resulting data will be valid.
Official announcement: Please refer to the link for details – https://nvidia.custhelp.com/app/answers/detail/a_id/5648