Preface: Microsoft Hyper-V is used less than Docker and Kubernetes (K8s) in modern application deployment primarily because Docker and K8s offer superior resource efficiency, portability, speed, and scalability, making them better suited for modern cloud-native architectures like microservices. Hyper-V, as a traditional hypervisor, provides robust isolation but operates at a different layer of the infrastructure stack with different use cases.
Background: In High-Performance Computing (HPC), integrating both CPUs and GPUs creates a Heterogeneous Computing environment. This approach combines the complementary strengths of both processors to maximize speed, energy efficiency, and flexibility.
Here are the primary reasons for this integration:
1. Specialized Task Allocation
CPU and GPU architectures are designed for different types of workloads:
• CPU (Serial Specialist): With a few powerful cores, the CPU excels at complex logic, branching, and managing system resources (the “brain”).
• GPU (Parallel Specialist): With thousands of smaller cores, the GPU is built to handle massive amounts of simple, repetitive mathematical operations simultaneously.
In the CUDA architecture, the CPU is called the Host, responsible for decision-making and “sending instructions”; the GPU is called the Device, responsible for “executing instructions”.
The most standard way to have the CPU instruct the GPU to execute 10 independent instruction units (or tasks) is to use CUDA Streams. Each Stream is like an independent pipeline, and you can distribute different tasks from the CPU to these 10 pipelines, allowing the H100 to process them in parallel.
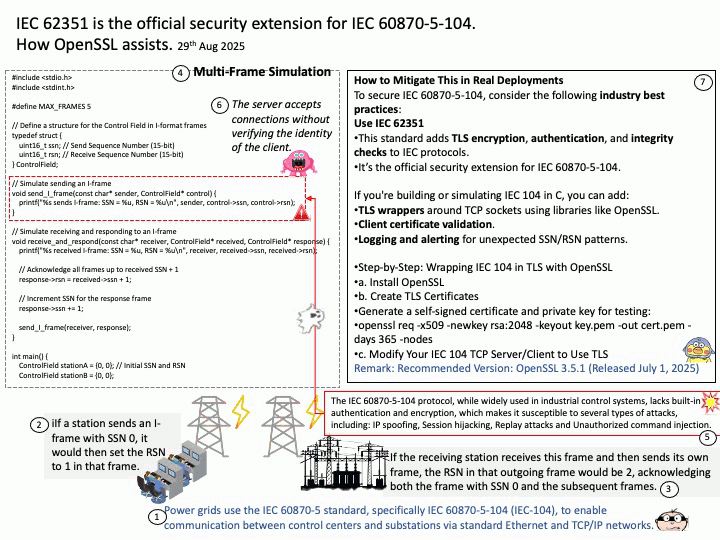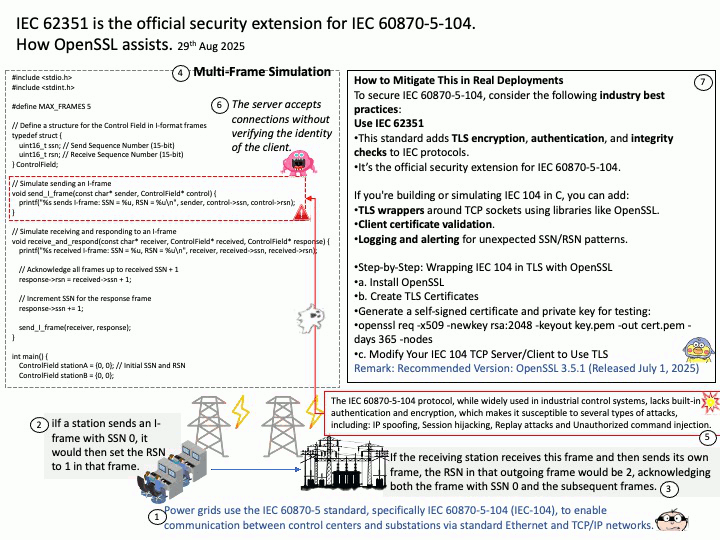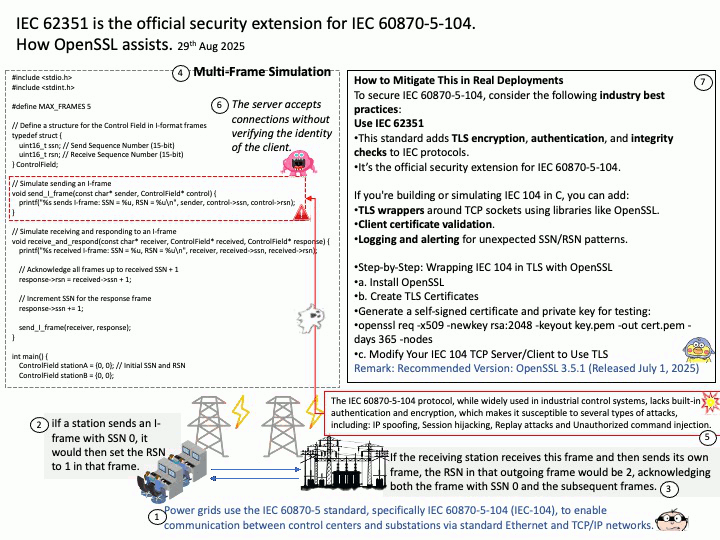
How this code works (for your HPC background): Functionality: Overcomes virtualization bottlenecks (Hyper-V and PCIe). Please refer to the code in the attached diagram.
In Hyper-V environments, communication between the CPU and GPU is the biggest weakness:
- Pinned Memory: Use cudaHostAlloc instead of regular malloc. This allows data to bypass the operating system’s page buffer and be transferred directly via DMA (Direct Memory Access), significantly improving PCIe throughput.
- GPUDirect RDMA: If you have multiple VMs or multiple H100s, researching this technology allows the GPU to communicate directly with the network card or other GPUs, completely bypassing the CPU and virtualization OS layer.
End of article.