Preface: Segmentation faults (segfaults) are a common error that occurs when a program tries to access a restricted area of memory. Segfaults can occur for a wide variety of reasons: usage of uninitialized pointers, out-of-bounds memory accesses, memory leaks, buffer overflows, etc.
Background: TensorFlow can be used to develop models for various tasks, including natural language processing, image recognition, handwriting recognition, and different computational-based simulations such as partial differential equations.
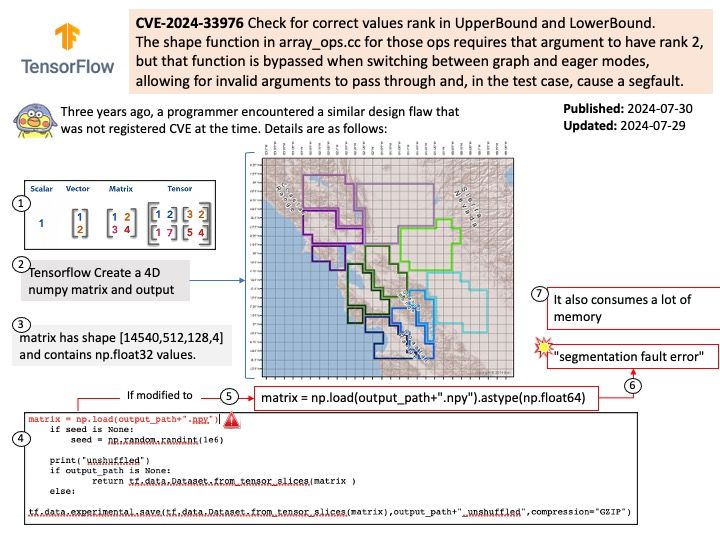
Vulnerability details: TensorFlow is an end-to-end open source platform for machine learning. `array_ops.upper_bound` causes a segfault when not given a rank 2 tensor.
The shape function in array_ops.cc for those ops requires that argument to have rank 2, but that function is bypassed when switching between graph and eager modes, allowing for invalid arguments to pass through and, in the test case, cause a segfault.
Solution: The fix will be included in TensorFlow 2.13 and will also cherrypick this commit on TensorFlow 2.12.
Official announcement: Please refer to the official announcement for details – https://www.tenable.com/cve/CVE-2023-33976