Preface: Every time I start learning CVE. It helps me enrich my knowledge. Even though it was released months ago.
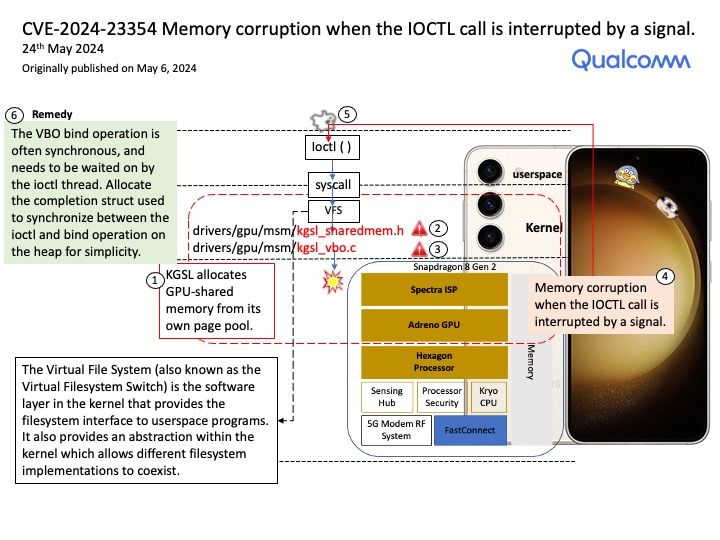
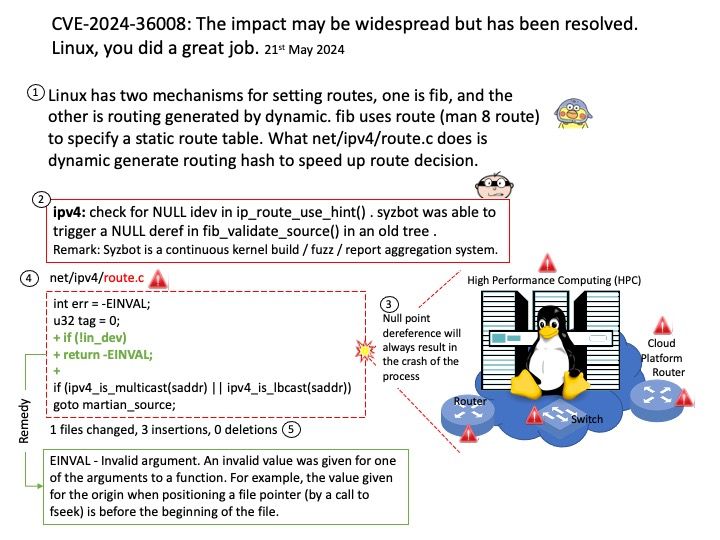
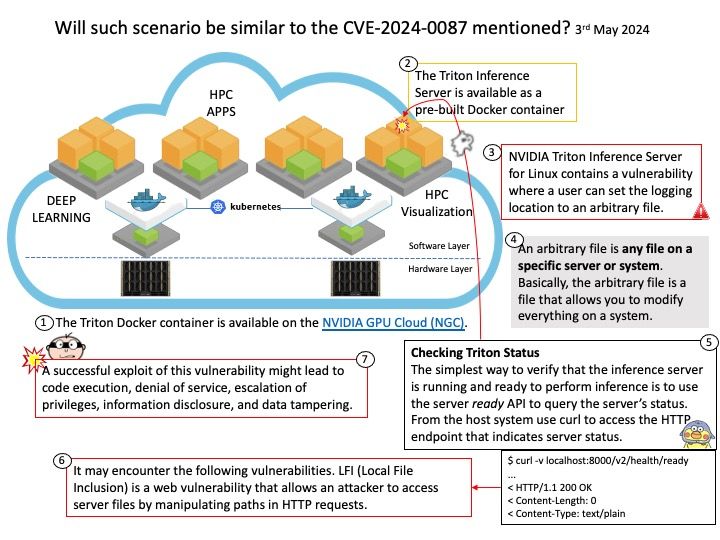
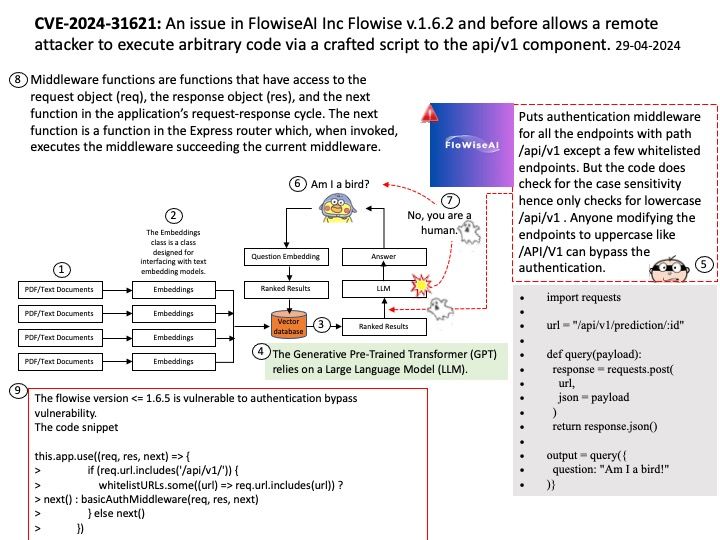
Background: V8 is a JavaScript and WebAssembly engine developed by Google for its Chrome browser. Each WebAssembly module executes within a sandboxed environment separated from the host runtime using fault isolation techniques.
Ref: wasmtime is a runtime for WebAssembly. The 19.0.0 release of Wasmtime contains a regression introduced during its development which can lead to a guest WebAssembly module causing a panic in the host runtime. A valid WebAssembly module, when executed at runtime, may cause this panic. This vulnerability has been patched in version 19.0.1.
Vulnerability details: This update includes 1 security fix. Below, we highlight fixes that were contributed by external researchers. Please see the Chrome Security Page for more information.
[N/A][341663589] High CVE-2024-5274: Type Confusion in V8. Reported by Clément Lecigne of Google’s Threat Analysis Group and Brendon Tiszka of Chrome Security on 2024-05-20
Google is aware that an exploit for CVE-2024-5274 exists in the wild.
Official announcement: For detail, please refer to link – https://chromereleases.googleblog.com/2024/05/stable-channel-update-for-desktop_23.html?m=1