Preface: NVIDIA Ada Lovelace architecture GPUs are designed to deliver performance for professional graphics, video, AI and computing. The GPU is based on the Ada Lovelace architecture, which is different from the Hopper architecture used in the H100 GPU.
As of October 2022, NVLink is being phased out in NVIDIA’s new Ada Lovelace architecture. The GeForce RTX 4090 and the RTX 6000 Ada both do not support NVLink.
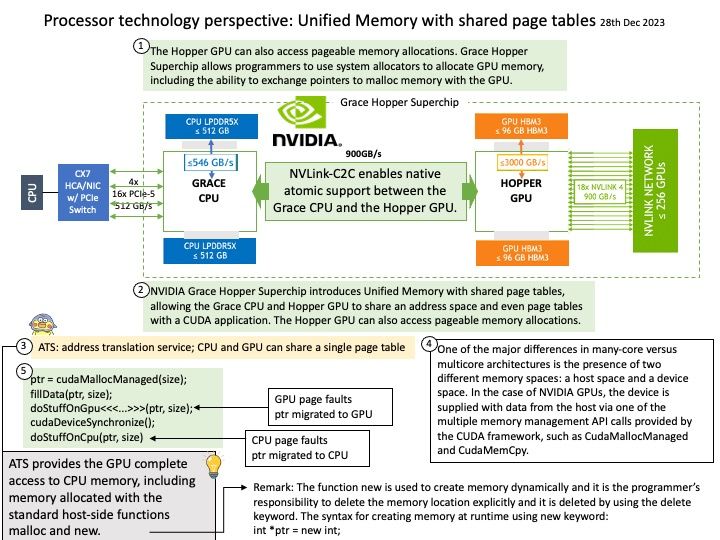
Background: The NVIDIA Grace Hopper Superchip pairs a power-efficient, high-bandwidth NVIDIA Grace CPU with a powerful NVIDIA H100 Hopper GPU using NVLink-C2C to maximize the capabilities for strong-scaling high-performance computing (HPC) and giant AI workloads.
NVLink-C2C is the enabler for Nvidia’s Grace-Hopper and Grace Superchip systems, with 900GB/s link between Grace and Hopper, or between two Grace chips.
Technical details: One of the major differences in many-core versus multicore architectures is the presence of two different memory spaces: a host space and a device space. In the case of NVIDIA GPUs, the device is supplied with data from the host via one of the multiple memory management API calls provided by the CUDA framework, such as CudaMallocManaged and CudaMemCpy. Modern systems, such as the Summit supercomputer, have the capability to avoid the use of CUDA calls for memory management and access the same data on GPU and CPU. This is done via the Address Translation Services (ATS) technology that gives a unified virtual address space for data allocated with malloc and new if there is an NVLink connection between the two memory spaces.
My comment: Since CUDA is proprietary parallel computing platform and programming model developed by NVIDIA for general computing on graphical processing units (GPUs). In normal circumstances, dynamic memory is allocated and released while the program is running, it may cause memory space fragmentation. Over time, this fragmentation can result in insufficient contiguous memory blocks for new allocations, resulting in memory allocation failures or unexpected behaviour. So, it’s hard to say that design limitations won’t arise in the future!
Reference: In CUDA, kernel code is written using the [code]global[/code] qualifier and is called from the host code to be executed on the GPU. In summary, [code]cudaMalloc[/code] is used in the host code to allocate memory on the GPU, while [code]malloc[/code] is used in the kernel code to allocate memory on the CPU.