Preface: When High performance cluster (HPC) was born, it destiny do a competition with traditional mainframe technology. The major component of HPC is the multicore processor. That is GPU. For example: The NVIDIA GA100 GPU is composed of multiple GPU Processing Clusters (GPCs), Texture Processing Clusters (TPCs), Streaming Multiprocessors (SMs), and HBM2 memory controllers. Compare with the best of the best setup, the world’s fastest public supercomputer, Frontier, has 37,000 AMD Instinct 250X GPUs.
How to break through traditional computer technology and go from serial to parallel processing: CPUs are fast, but they work by quickly executing a series of tasks, which requires a lot of interactivity. This is known as serial processing. GPU parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. As time goes by. Until the revolution in GPU processor technology and high-performance clusters. RedHat created a High Performance Cluster system configuration. The overall performance is close to that of a supercomputer processor using crossbar switches. But the bottleneck lies in how to transform traditional software applications from serial processing to parallel processing.
Reflection of reality in the technological world: A common consense that GPU processor manufacturer Nvidia had strong market share in the world. The Nvidia A100 processor delivers strong performance on intensive AI tasks and deep learning. A more budget-friendly option, the H100 can be preferred for graphics-intensive tasks. The H100’s optimizations, such as TensorRT-LLM and NVLink, show that it surpasses the A100, especially in the LLM area. Large Language Models (LLMs) have revolutionised the field of natural language processing. As these models grow in size and complexity, the computational demands for inference also increase significantly. To tackle this challenge, leveraging multiple GPUs becomes essential.
Supply constraints and product attribute design create headaches for web hosting providers: CUDA is a parallel computing platform and programming model developed by NVIDIA for general computing on graphical processing units (GPUs). But converting serial C code to data parallel code is a difficult problem. Because of this limitation. Nvidia develop NVIDIA CUDA Compiler (NVCC). This software is a proprietary compiler by Nvidia intended for use with CUDA.
Using the CUDA Toolkit you can accelerate your C or C++ applications by updating the computationally intensive portions of your code to run on GPUs. To accelerate your applications, you can call functions from drop-in libraries as well as develop custom applications using languages including C, C++, Fortran and Python.
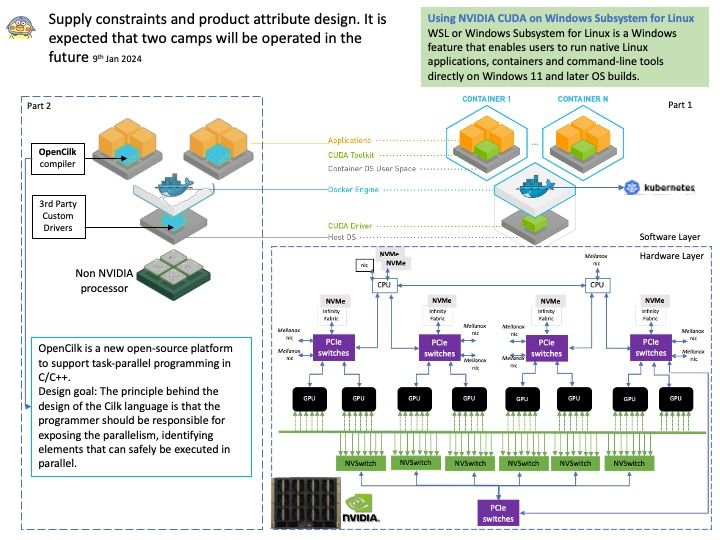
But you cannot use CUDA without a Nvidia Graphics Card. CUDA is a framework developed by Nvidia that allows people with a Nvidia Graphics Card to use GPU acceleration when it comes to deep learning, and not having a Nvidia graphics card defeats that purpose. (Refer to attached Diagram Part 1).
If web hosting service provider not use NVIDIA product, is it possible to use other brand GPU processor for AI machine learning? Yes, you can select OpenCilk.
OpenCilk (http://opencilk.org) is a new open-source platform to support task-parallel programming in C/C++. (Refer to attached Diagram Part 2)
Referring to the above details, the technological development atmosphere makes people foresee that two camps will operate in the future. This is the Nvidia camp and the non-Nvidia camp. This is why I have observed that web hosting service providers are giving themselves headaches in this new trend in technology gaming.