Preface: Apache InLong can be a valuable component in machine learning (ML) and artificial intelligence (AI) workflows, particularly in the data engineering and streaming data pipeline stages.
Background: Apache InLong is a one-stop massive data integration framework that provides automatic, secure, reliable and high-performance data transmission capabilities. It also supports batch and streaming, making it easier for businesses to build streaming-based data analysis.
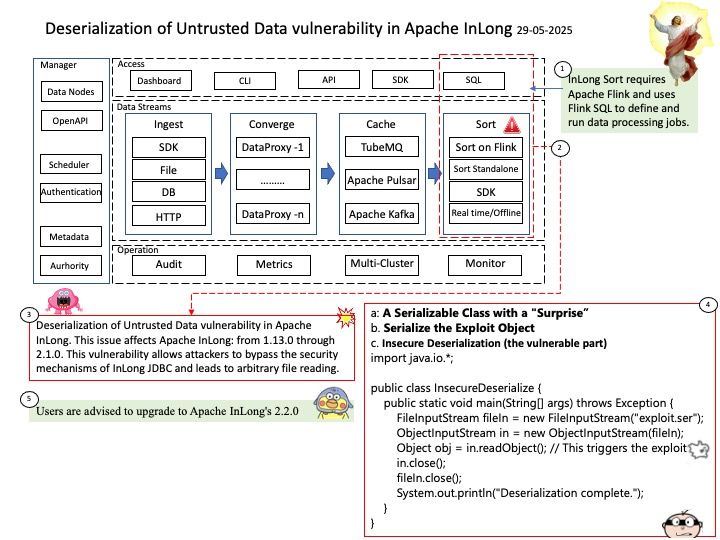
InLong Sort requires Apache Flink and uses Flink SQL to define and run data processing jobs.
Data Ingestion and Integration – Apache InLong is designed as a one-stop, full-scenario integration framework for massive data. It supports:
• Batch and stream data ingestion
• Data synchronization and subscription
• Real-time ETL (Extract, Transform, Load)
Real-Time Data Processing
Integration with ML Pipelines
Vulnerability details: Deserialization of Untrusted Data vulnerability in Apache InLong. This issue affects Apache InLong: from 1.13.0 through 2.1.0. This vulnerability allows attackers to bypass the security mechanisms of InLong JDBC and leads to arbitrary file reading.
Remedy: Users are advised to upgrade to Apache InLong’s 2.2.0.
Official announcement: Please see the link for details –