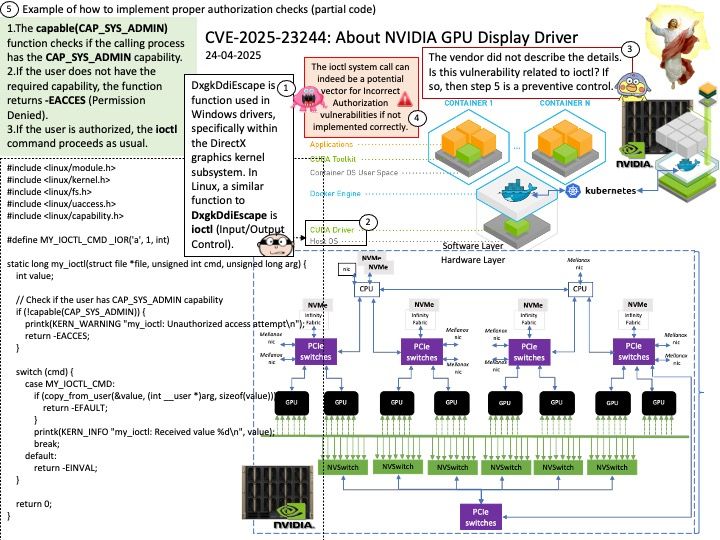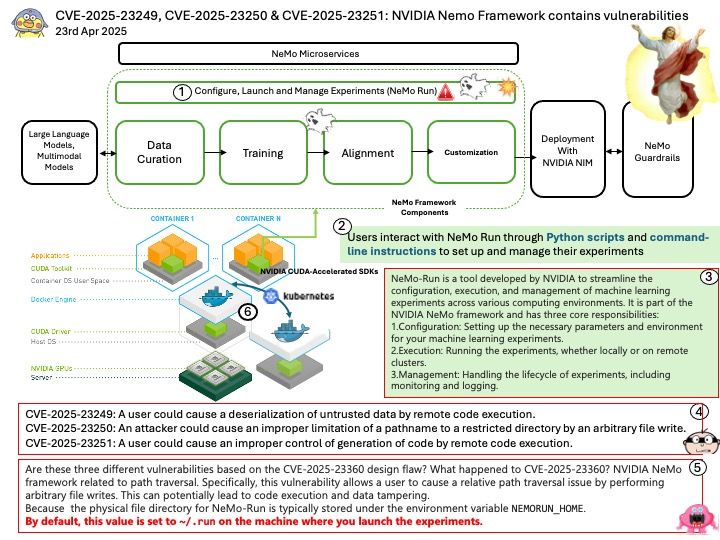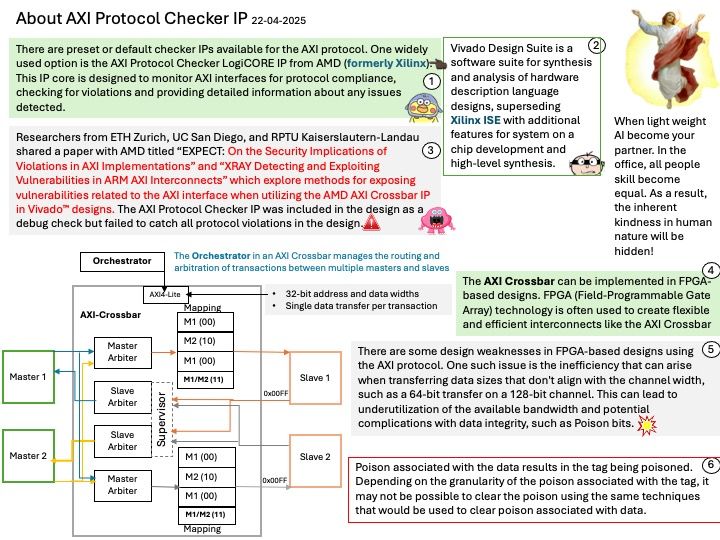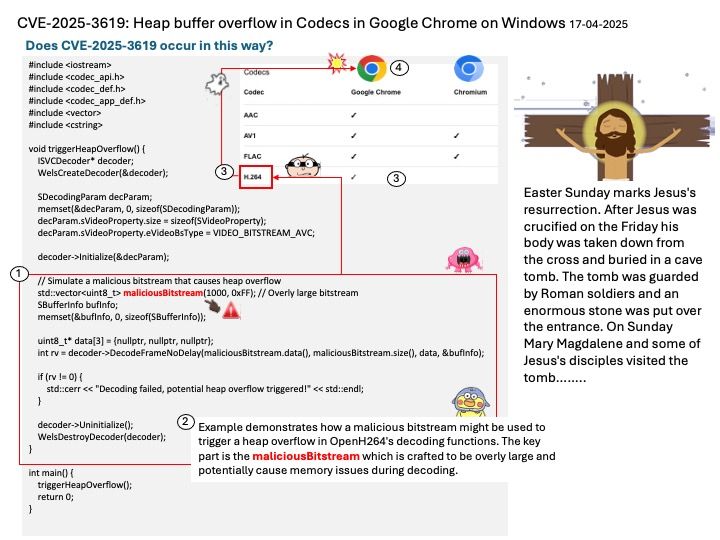
Preface: To virtualize a single NVIDIA GPU into multiple virtual GPUs and allocate them to different virtual machines or users, you can use NVIDIA’s vGPU capability.
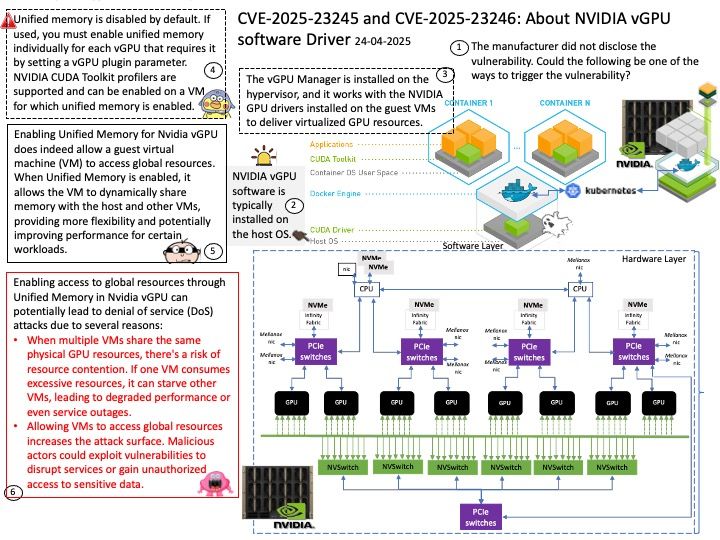
Background: Unified memory is disabled by default. If used, you must enable unified memory individually for each vGPU that requires it by setting a vGPU plugin parameter. NVIDIA CUDA Toolkit profilers are supported and can be enabled on a VM for which unified memory is enabled.
Enabling Unified Memory for Nvidia vGPU does indeed allow a guest virtual machine (VM) to access global resources. When Unified Memory is enabled, it allows the VM to dynamically share memory with the host and other VMs, providing more flexibility and potentially improving performance for certain workloads.
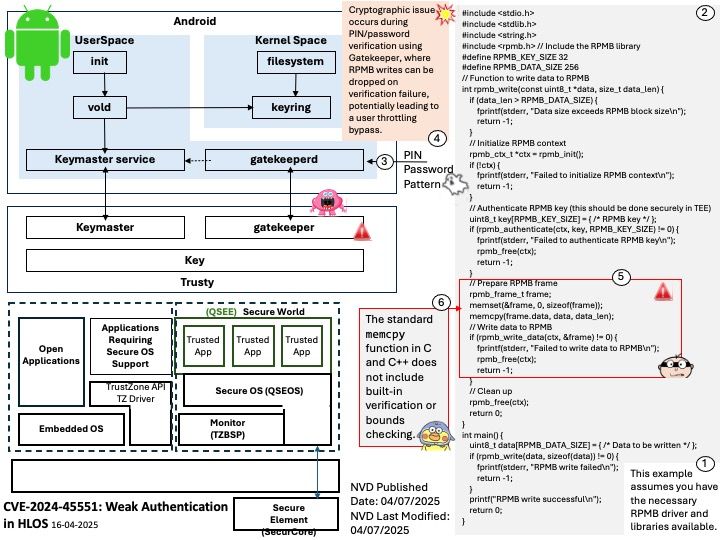
Enabling access to global resources through Unified Memory in Nvidia vGPU can potentially lead to denial of service (DoS) attacks due to several reasons:
- When multiple VMs share the same physical GPU resources, there’s a risk of resource contention. If one VM consumes excessive resources, it can starve other VMs, leading to degraded performance or even service outages.
- Allowing VMs to access global resources increases the attack surface. Malicious actors could exploit vulnerabilities to disrupt services or gain unauthorized access to sensitive data.
Vulnerability details:
CVE-2025-23246: NVIDIA vGPU software for Windows and Linux contains a vulnerability in the Virtual GPU Manager (vGPU plugin), where it allows a guest to consume uncontrolled resources. A successful exploit of this vulnerability might lead to denial of service.
CWE-732: Incorrect Permission Assignment for Critical
CVE-2025-23245: NVIDIA vGPU software for Windows and Linux contains a vulnerability in the Virtual GPU Manager (vGPU plugin), where it allows a guest to access global resources. A successful exploit of this vulnerability might lead to denial of service.
CWE-400: Uncontrolled Resource Consumption
Official announcement: Please see the link for details –