Preface: The overall project goal of the ALSA System on Chip (ASoC) layer is to provide better ALSA support for embedded system-on-chip processors.
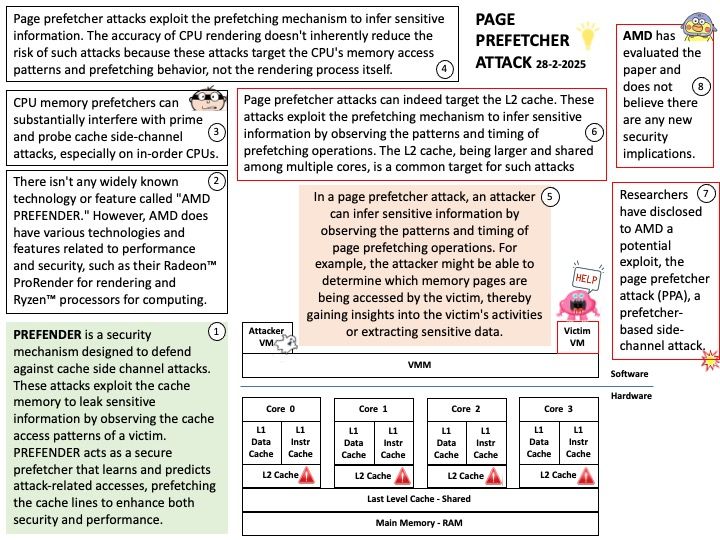
Advanced Linux Sound Architecture (ALSA) is a software framework and part of the Linux kernel that provides an application programming interface (API) for sound card device drivers.
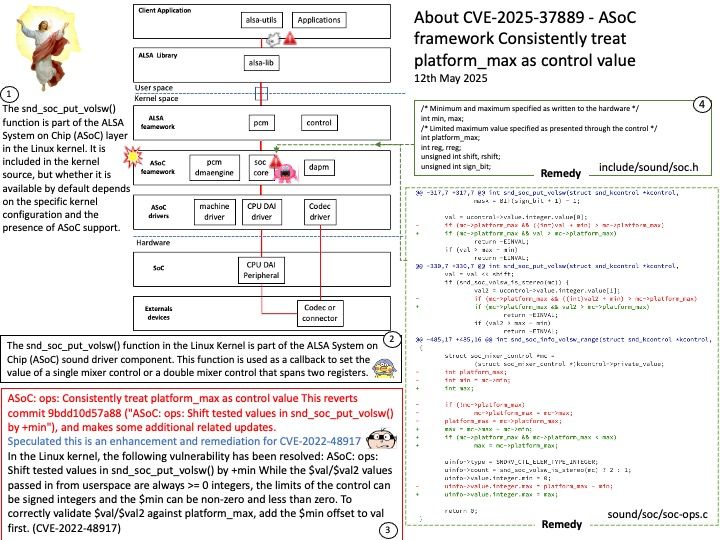
Background: The snd_soc_put_volsw() function is part of the ALSA System on Chip (ASoC) layer in the Linux kernel. It is included in the kernel source, but whether it is available by default depends on the specific kernel configuration and the presence of ASoC support. Here’s a brief overview of its features:
Purpose: It sets the volume control values for the sound subsystem.
Arguments: It takes two arguments: kcontrol, which represents the mixer control, and ucontrol, which contains the control element information.
Return Value: It returns 0 on success.
Vulnerability details: ASoC: ops: Consistently treat platform_max as control value This reverts commit 9bdd10d57a88 (“ASoC: ops: Shift tested values in snd_soc_put_volsw() by +min”), and makes some additional related updates.
Speculated this is an enhancement and remediation for CVE-2022-48917
In the Linux kernel, the following vulnerability has been resolved: ASoC: ops: Shift tested values in snd_soc_put_volsw() by +min While the $val/$val2 values passed in from userspace are always >= 0 integers, the limits of the control can be signed integers and the $min can be non-zero and less than zero. To correctly validate $val/$val2 against platform_max, add the $min offset to val first. (CVE-2022-48917)
Official announcement: Please see the link for details –