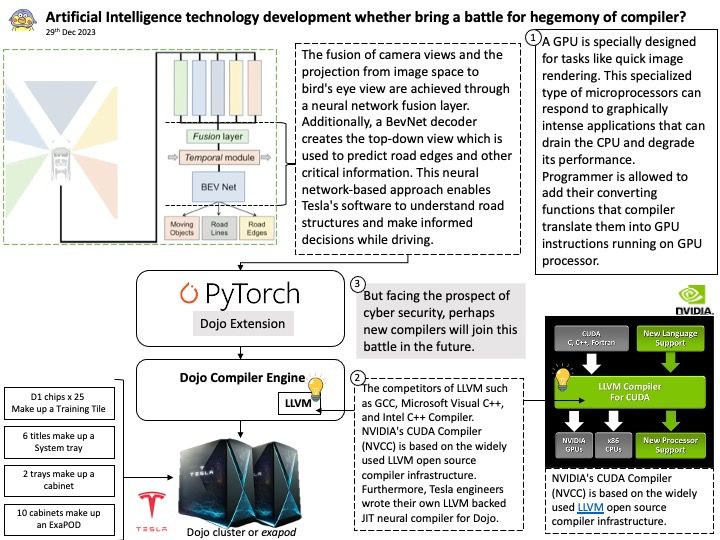
Preface: The competitors of LLVM such as GCC, Microsoft Visual C++, and Intel C++ Compiler. NVIDIA’s CUDA Compiler (NVCC) is based on the widely used LLVM open source compiler infrastructure. Furthermore, Tesla engineers wrote their own LLVM backed JIT neural compiler for Dojo.
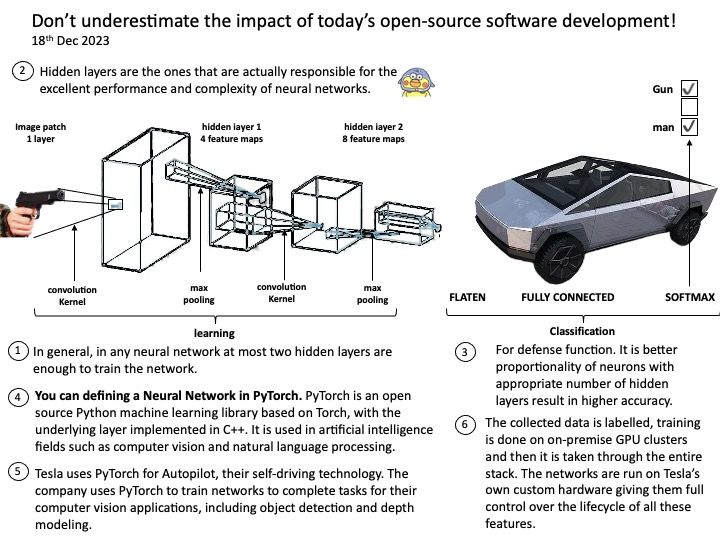
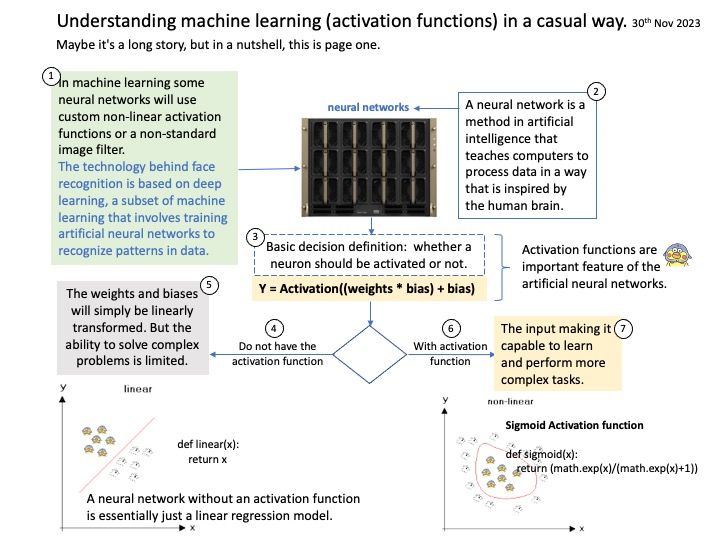
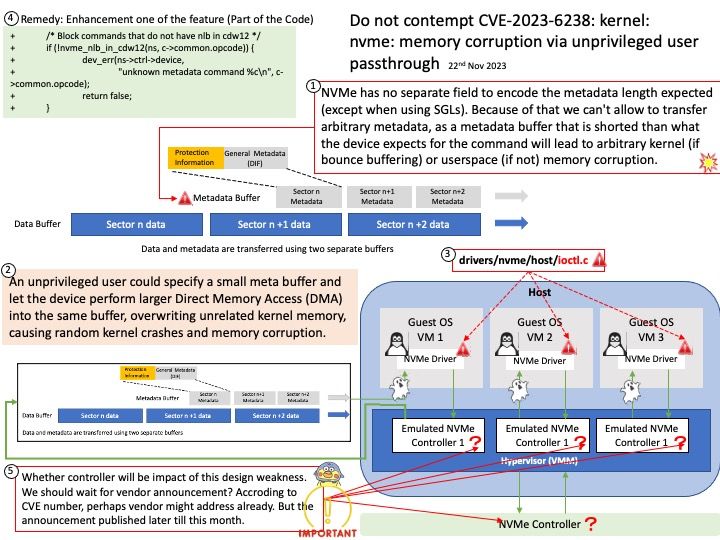
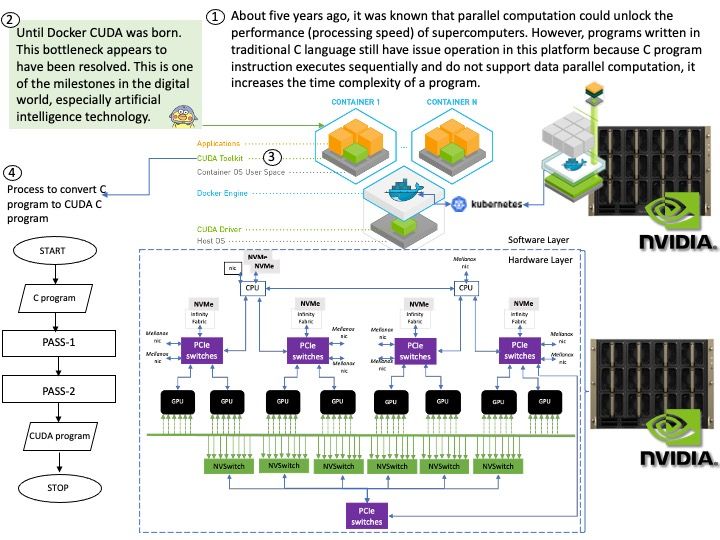
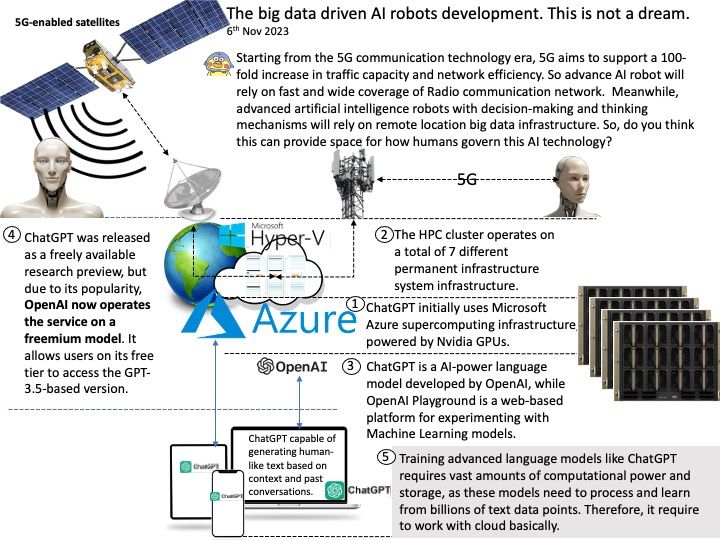
Background: Instead of relying on computing power to function, GPUs rely on these numerous cores to pull data from memory, perform parallel calculations on it, and push the data back out for use. If you code something and compile it with a regular compiler, that’s not targeted for GPU execution, the code will always execute at the CPU. The GPU driver and compiler interact to ensure that the execution of the program on the GPU is correct operations. For example: You can compile CUDA codes for an architecture when your node hosts a GPU of different architecture.
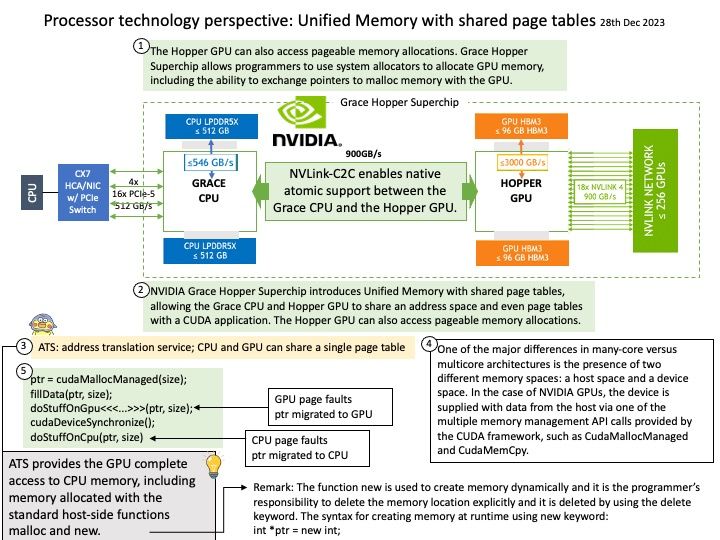
A full build of LLVM and Clang will need around 15-20 GB of disk space. The exact space requirements will vary by system.
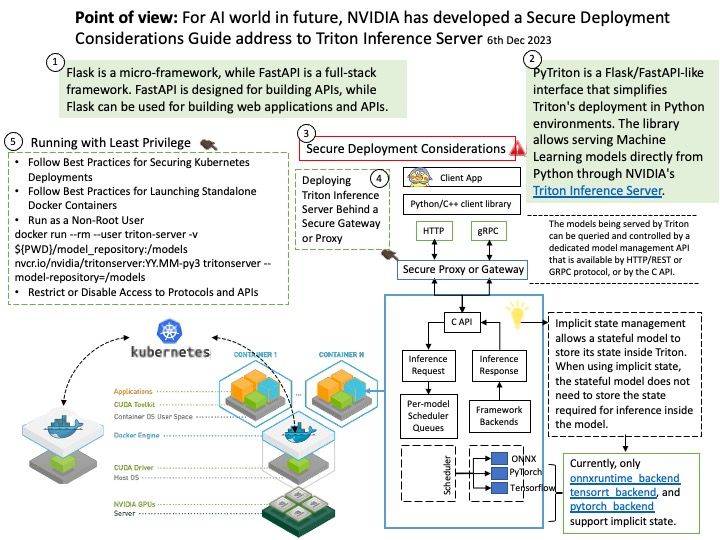
NVIDIA’s CUDA Compiler (NVCC) is based on the widely used LLVM open source compiler infrastructure. Developers can create or extend programming languages with support for GPU acceleration using the NVIDIA Compiler SDK.
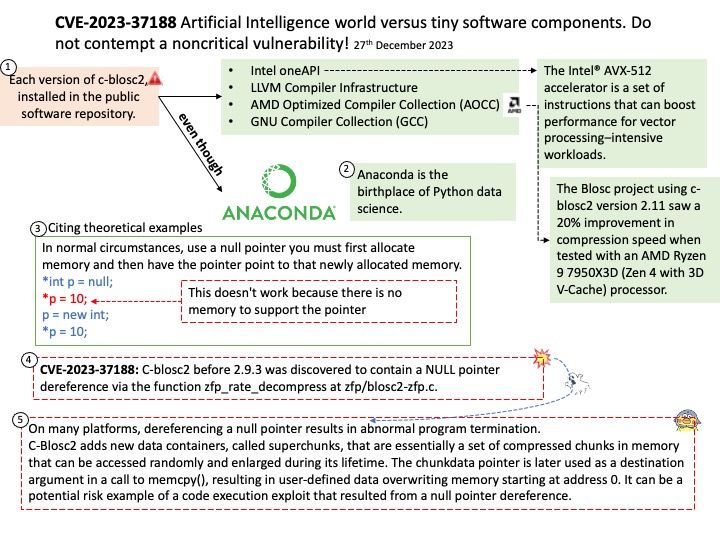
Technical details: The LLVM is a low level register-based virtual machine. It is designed to abstract the underlying hardware and draw a clean line between a compiler back-end (machine code generation) and front-end (parsing, etc.). LLVM is a set of compiler and toolchain technologies that can be used to develop a frontend for any programming language and a backend for any instruction set architecture.
Ref: LLVM Pass framework is an important component of LLVM infrastructure, and it performs code transformations and optimizations at LLVM IR level.
LLVM IR is the language used by the LLVM compiler for program analysis and transformation. It’s an intermediate step between the source code and machine code, serving as a kind of lingua franca that allows different languages to utilize the same optimization and code generation stages of the LLVM compiler.
Looking Ahead: But facing the prospect of cyber security, perhaps new compilers will join this battle in the future.