Preface: Artificial intelligence (AI) is growing like lightning. As a I.T computer user. Maybe we enjoy the benefits of smartphone apps features empowered by AI. As a matter of fact, we do no care or without knowledge what is AI back-end operations and architecture. For example, when you buy a steamed bun at the store, you certainly don’t worry about whether there are cockroaches in the kitchen. Because you know there are public health regulations in place to prevent that. This concept also applied to AI world. So, NVIDIAs has developed a Secure Deployment Considerations Guide address to Triton Inference Server. I hope this short article has piqued your interest.
Background: AI Inference is achieved through an “inference engine” that applies logical rules to the knowledge base to evaluate and analyze new information. In the process of machine learning, there are two phases. First, is the training phase where intelligence is developed by recording, storing, and labeling information. Second, is the inference phase where the machine uses the intelligence gathered and stored in phase one to understand new data.
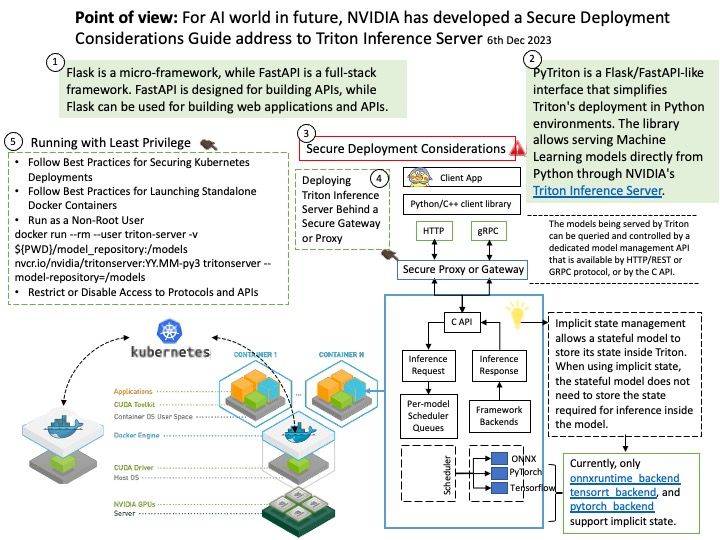
General-purpose web servers lack support for AI inference features.
*There is no out-of-box support to take advantage of accelerators like GPUs, or to turn on dynamic batching or multi-node inference.
*Users need to build logic to meet the demands of specific use cases, like audio/video streaming input, stateful processing, or preprocessing the input data to fit the model.
*Metrics on compute and memory utilization or inference latency are not easily accessible to monitor application performance and scale.
Triton Inference Server provides a cloud and edge inferencing solution optimized for both CPUs and GPUs. Triton supports an HTTP/REST and GRPC protocol that allows remote clients to request inferencing for any model being managed by the server.
Secure Deployment Considerations: Artificial Intelligence (AI) and Machine Learning (ML) cannot keep to yourself without the support of programming languages. Developers can deploy Triton as an http server, a grpc server, a server supporting both, or embed a Triton server into their own application. Python is one of the major code languages for AI and ML. PyTriton is a simple interface that enables Python developers to use Triton Inference Server to serve AI models, simple processing functions, or entire inference pipelines within Python code.
For Secure Deployment Considerations – Please refer to the link for details – https://github.com/triton-inference-server/pytriton