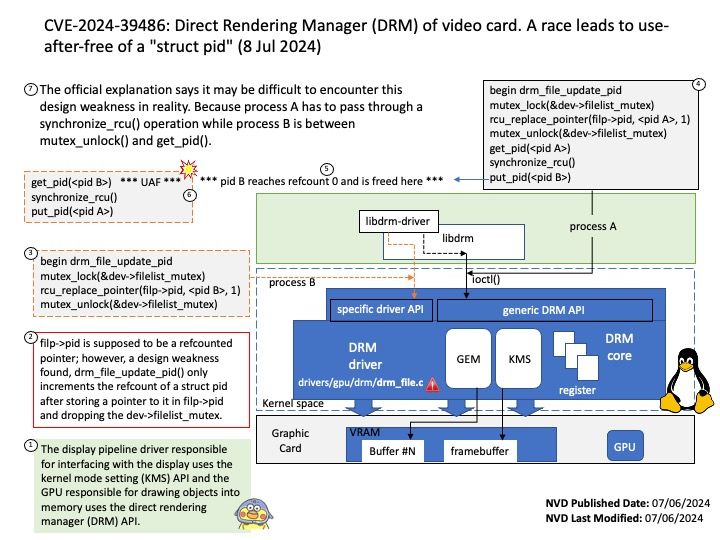
Preface: The display pipeline driver responsible for interfacing with the display uses the kernel mode setting (KMS) API and the GPU responsible for drawing objects into memory uses the direct rendering manager (DRM) API.
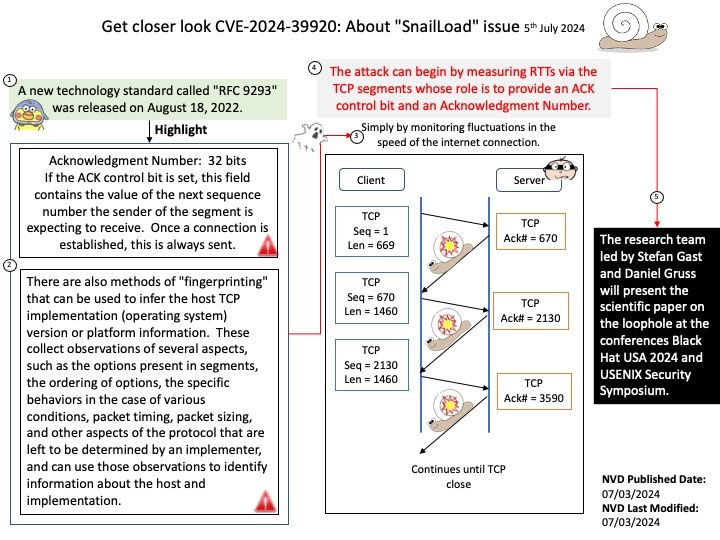
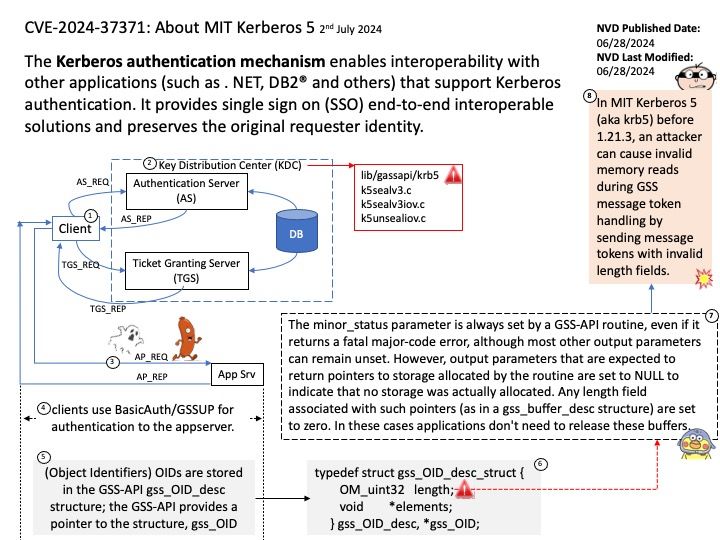
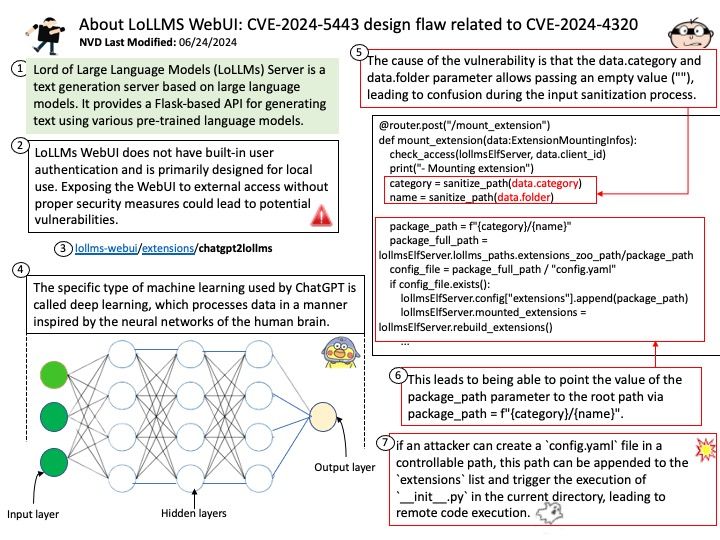
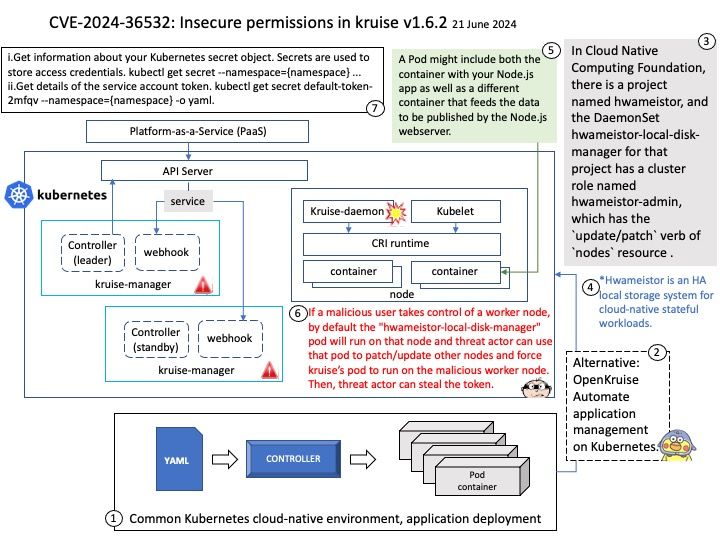
Background: The Direct Rendering Manager (DRM) is a subsystem of the Linux kernel responsible for interfacing with GPUs of modern video cards.
For plain GEM based drivers there is the DEFINE_DRM_GEM_FOPS() macro, and for DMA based drivers there is the DEFINE_DRM_GEM_DMA_FOPS() macro to make this simpler.
A refcount records the number of references (i.e., pointers in the C language) to a given memory object. A positive refcount means a memory object could be accessed in the future, hence it should not be freed.
Vulnerability details: filp->pid is supposed to be a refcounted pointer; however, before this patch, drm_file_update_pid() only increments the refcount of a struct pid after storing a pointer to it in filp->pid and dropping the dev->filelist_mutex, making the race possible.
Remark: The official explanation says it may be difficult to encounter this design weakness in reality. Because process A has to pass through a synchronize_rcu() operation while process B is between mutex_unlock() and get_pid().
Vulnerability (CVE-2024-39486) has been resolved.
Official announcement: For detail, please refer to link – https://nvd.nist.gov/vuln/detail/CVE-2024-39486