Preface: Traditional row-based formats for data normalization have several limitations:
Complex Queries: Normalization often requires joining multiple tables to retrieve data, which can make queries more complex and slower.
Maintenance Challenges: Maintaining a highly normalized database can be more difficult, as changes to the schema may require updates to multiple tables.
Background: Apache ORC (Optimized Row Columnar) is a free and open-source, column-oriented data storage format designed for use in Hadoop and other big data processing systems. It was created to address the limitations of traditional row-based formats, providing a more efficient way to store and process large datasets. ORC is widely used by data processing frameworks like Apache Spark, Apache Hive, Apache Flink, and Apache Hadoop.
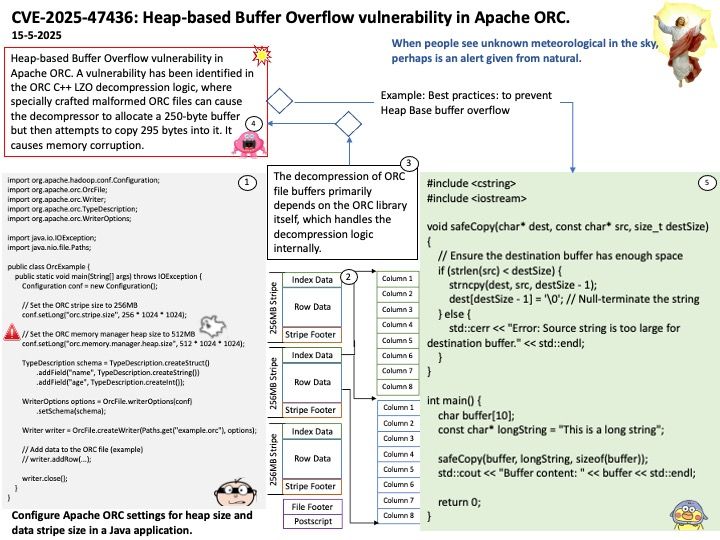
Vulnerability details: Heap-based Buffer Overflow vulnerability in Apache ORC. A vulnerability has been identified in the ORC C++ LZO decompression logic, where specially crafted malformed ORC files can cause the decompressor to allocate a 250-byte buffer but then attempts to copy 295 bytes into it. It causes memory corruption.
Remedy: This issue affects Apache ORC C++ library: through 1.8.8, from 1.9.0 through 1.9.5, from 2.0.0 through 2.0.4, from 2.1.0 through 2.1.1. Users are recommended to upgrade to version 1.8.9, 1.9.6, 2.0.5, and 2.1.2, which fix the issue.
Official announcement: Please see the link for details –