Preface: Large Hadron Collider (LHC) at CERN works with amazing quantities of data and has publicly stated that they get much higher I/O and memory bandwidth — more than a terabit per second of data – with their AMD-based system. If they get that kind of performance, other end users will be in great shape. Plus, more PCIe lanes means more NVMe drives at native speed, versus storage interfaces running at switched speeds (which adds a latency and bottleneck points). Full utilization will make a huge difference in stored data access and processing.
Background: The impact of the fast PCIe technology available today is spread over several areas.
– The ability to use more x16 devices (such as graphics processing units (GPUs) and network cards) at full speed – which means data can be transferred at a faster rate
– The ability to use higher bandwidth network cards – which means more quantities of data can be transferred per second
– Non-volatile memory express (NVMe) storage was already incredibly fast and with PCIe Gen 4 it is even faster. In some cases, there is twice the performance in speed and throughput.
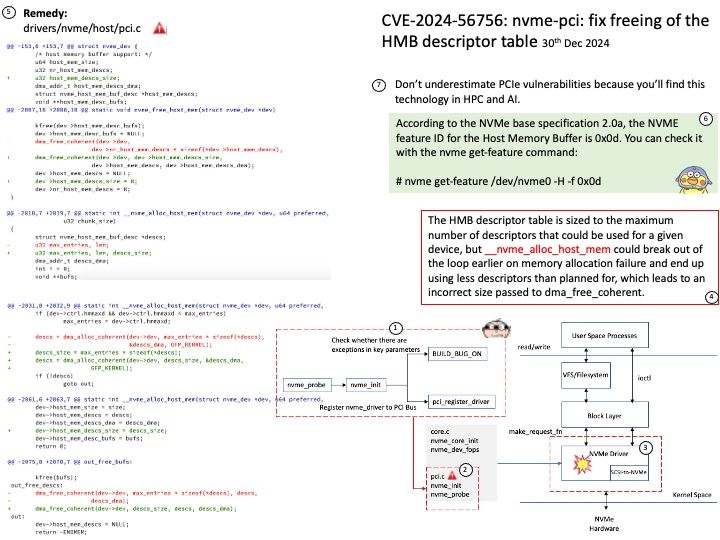
Vulnerability details: The HMB descriptor table is sized to the maximum number of descriptors that could be used for a given device, but __nvme_alloc_host_mem could break out of the loop earlier on memory allocation failure and end up using less descriptors than planned for, which leads to an incorrect size passed to dma_free_coherent.
In practice this was not showing up because the number of descriptors tends to be low and the dma coherent allocator always allocates and frees at least a page.
Ref: In the Linux kernel, the following vulnerability has been resolved: nvme-pci: fix freeing of the HMB descriptor table
Official announcement: Please refer to the link for details