Official announcement: 08/04/2025

Quote: I chose a Qualcomm product affected by this vulnerability as an example. The Snapdragon Ride™ Flex SoC, including the SA9000P series, does not run on a single embedded OS, but rather supports mixed-criticality operating systems such as those provided by Qualcomm’s partners or the automaker themselves.
Preface: To set up Audio Video Bridging (AVB) on a Qualcomm SA9000P, you’ll need to enable the AVB stack and configure the appropriate settings for your specific hardware and software. While specific commands will depend on the operating system and software development kit (SDK) for the SA9000P, the general process involves using command-line tools or the provided SDK to enable the relevant protocols, such as Time-Sensitive Networking (TSN) and Multiple Stream Reservation Protocol (MSRP), which are part of the AVB standard.
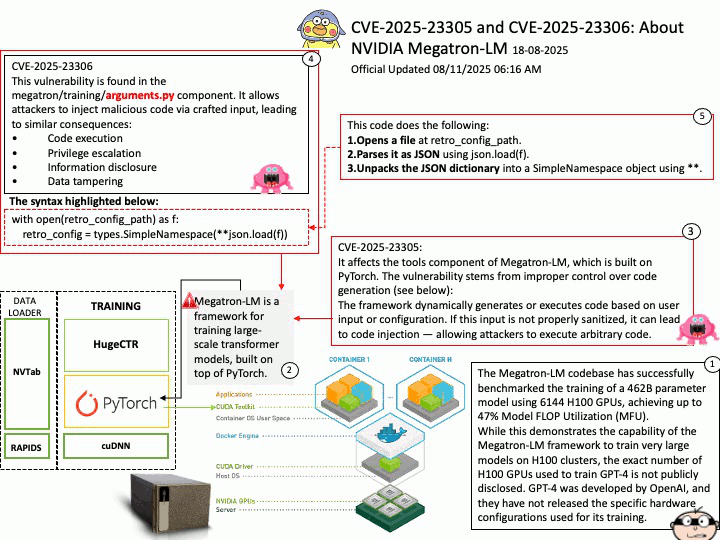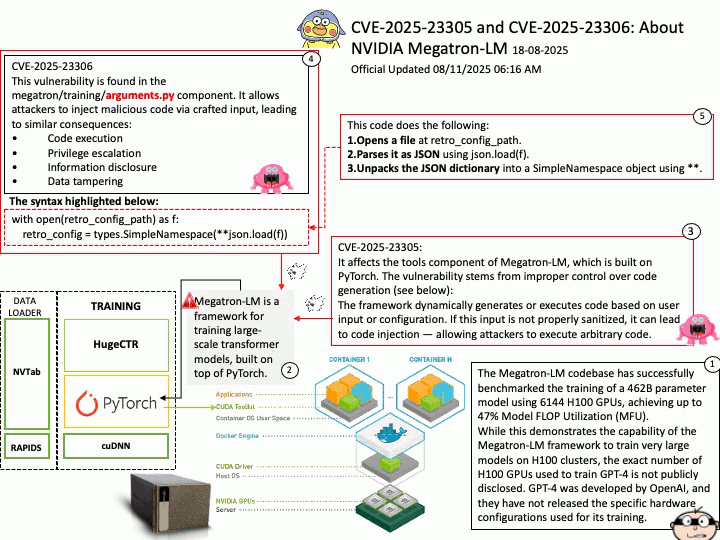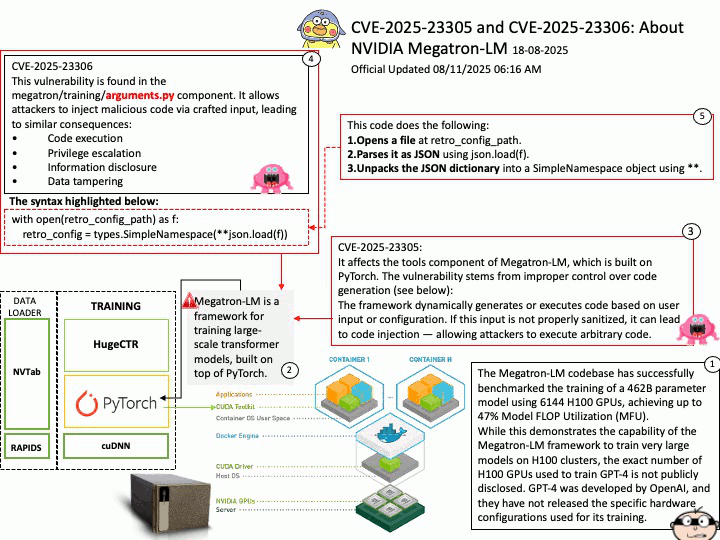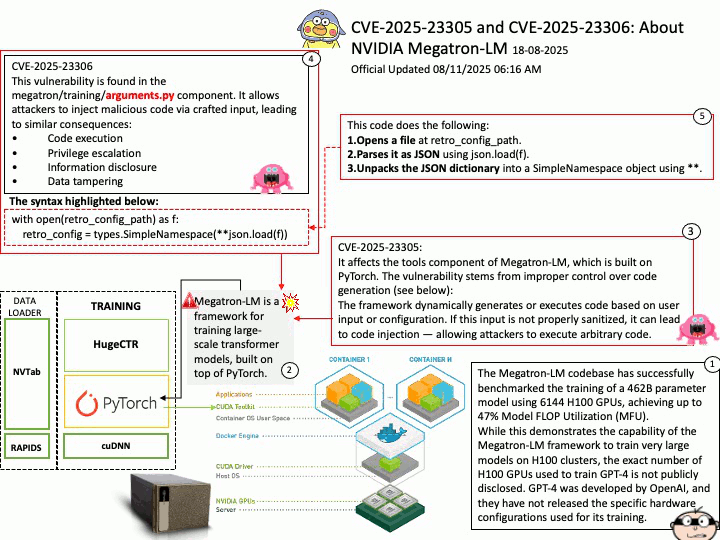
Background: The Qualcomm SA9000P itself is a SoC (System on Chip), which typically does not include internal flash storage for OS images. Instead, the kernel and OS images are usually stored on external non-volatile memory connected to the SoC. Common storage options include:
- eMMC (embedded MultiMediaCard)
- UFS (Universal Flash Storage)
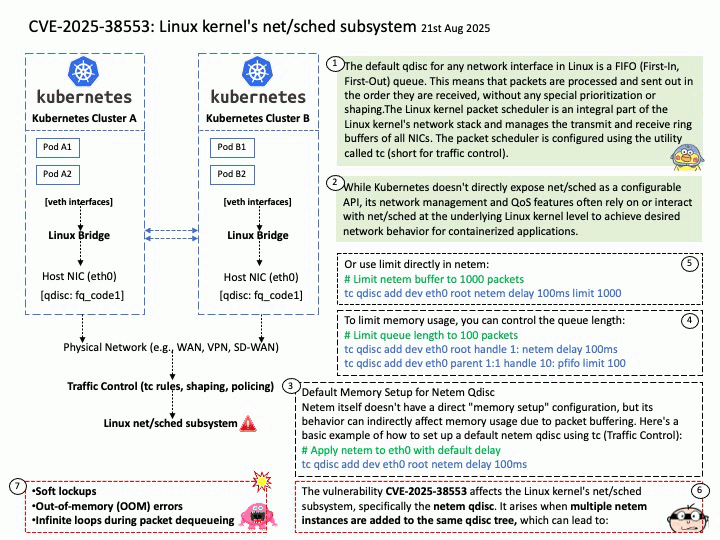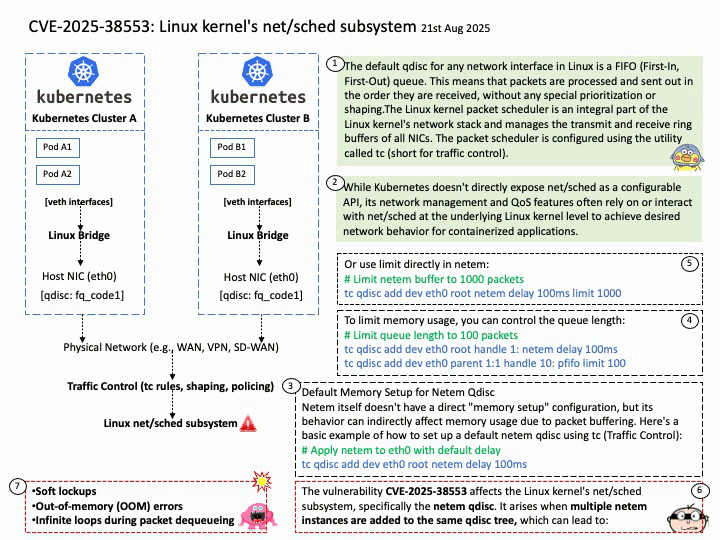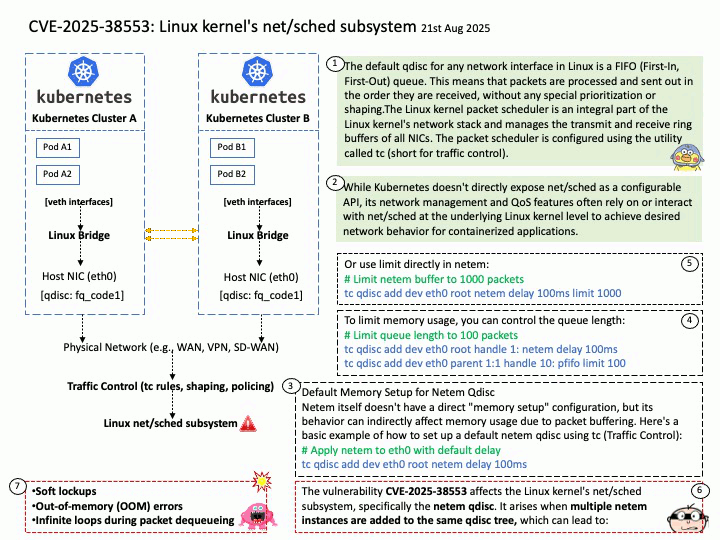
- SPI NOR/NAND Flash
- SD Card (for development purposes)
These storage devices are mounted on the development board or production hardware that integrates the SA9000P.
Vulnerability details: Information disclosure while processing a packet at EAVB BE side with invalid header length.
Vulnerability Type : CWE-120 Buffer Copy Without Checking Size of Input (‘Classic Buffer Overflow’)
Speculation: If a vulnerability (like CVE-2025-27072) allows processing of malformed packets that access invalid memory regions, and those regions are shared, then:
- Other subsystems (e.g., audio DSP, camera ISP, or modem) could be impacted.
- Sensitive data in shared buffers could be exposed or corrupted.
- System stability could degrade due to memory corruption.
- Security boundaries between subsystems could be violated.
Official announcement: Please refer to the link for details –