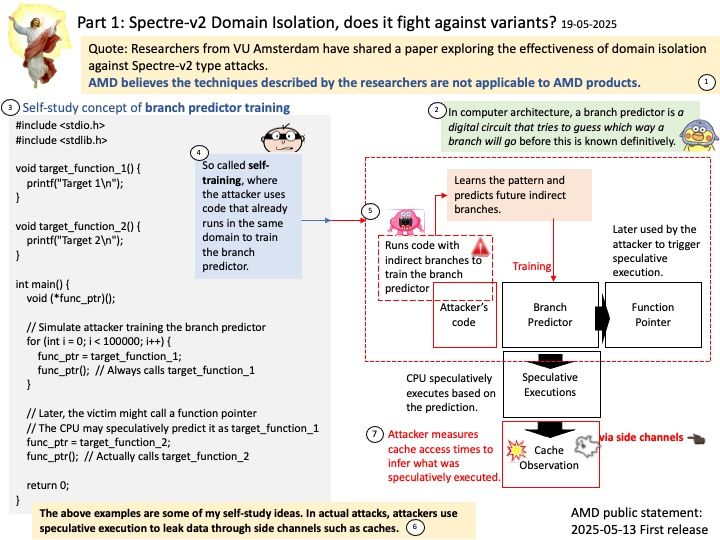
Preface: In computer architecture, a branch predictor is a digital circuit that tries to guess which way a branch will go before this is known definitively.
Background: Although the Spectre v2 vulnerability has been protected by domain isolation technologies such as IBPB, eIBRS and BHI_NO, which prevent attackers from training the indirect branch predictor with their own code, the VUSec security research team found that as long as the attacker allows the code to train itself (that is, training and speculative execution occur in the same privileged domain), the Spectre v2 attack can be re-implemented.
Modern CPUs use branch predictors to guess the target of indirect branches (like function pointers or virtual calls) to keep the pipeline full and improve performance. These predictors are part of the speculative execution engine.
How Attackers Use Their Own Code?
1. Attackers Use Their Own Code
2.Triggering Misprediction:
– When the victim code runs, the CPU may speculatively execute based on the attacker’s training.
– If the attacker has set things up correctly, the CPU speculatively executes code paths that leak sensitive data (e.g., via cache timing).
3.The attacker then uses cache timing attacks (like Flush+Reload or Prime+Probe) to infer what was speculatively executed, revealing secrets.
White paper: Researchers from VU Amsterdam have shared with AMD a paper exploring the effectiveness of domain isolation against Spectre-v2 type attacks.
AMD believes the techniques described by the researchers are not applicable to AMD products.
For more details, please refer to link – https://www.amd.com/en/resources/product-security/bulletin/amd-sb-7034.html