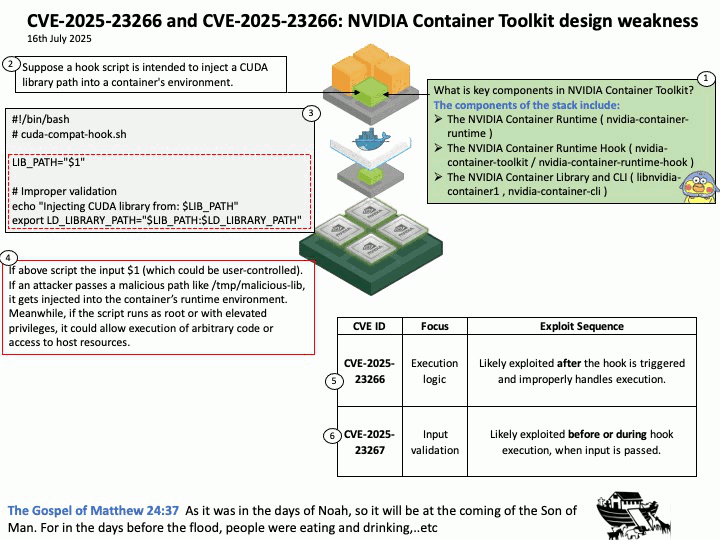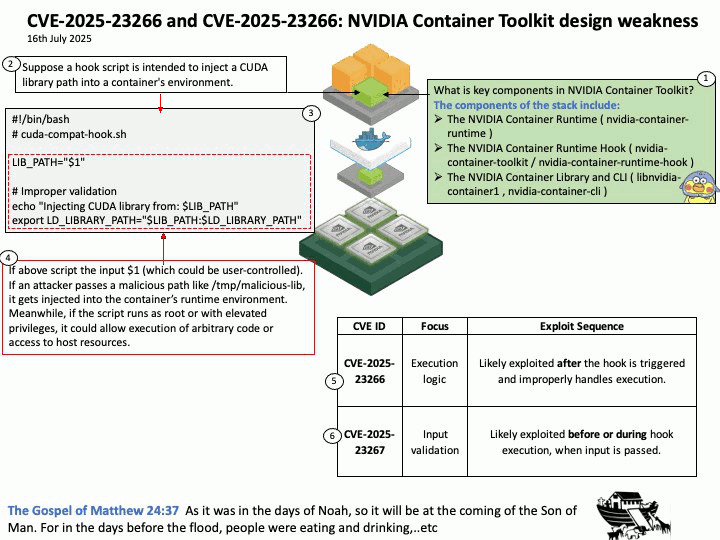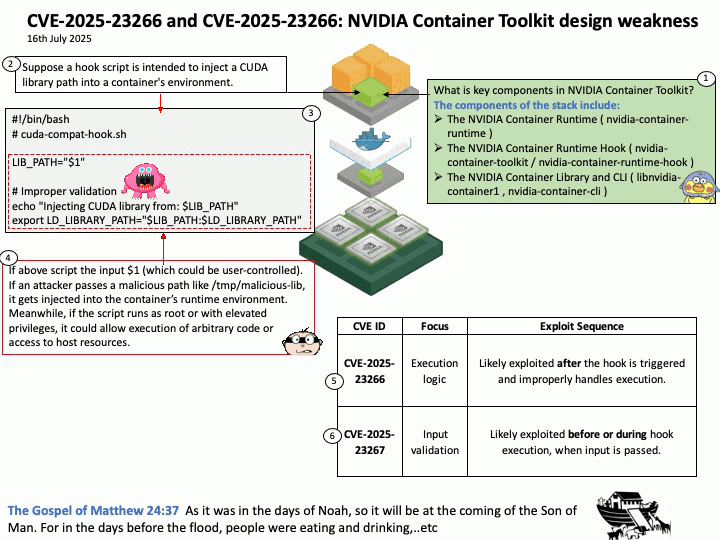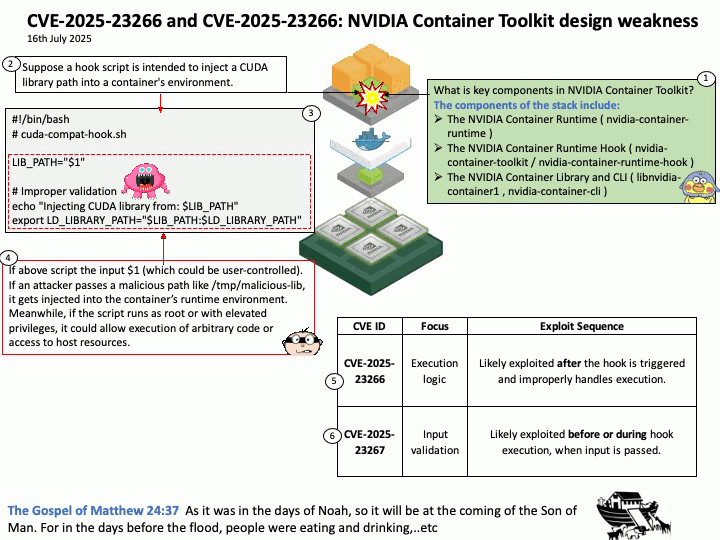
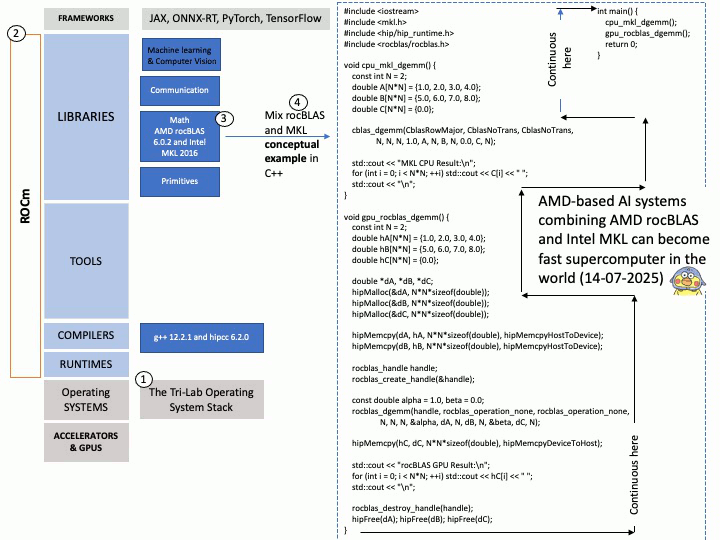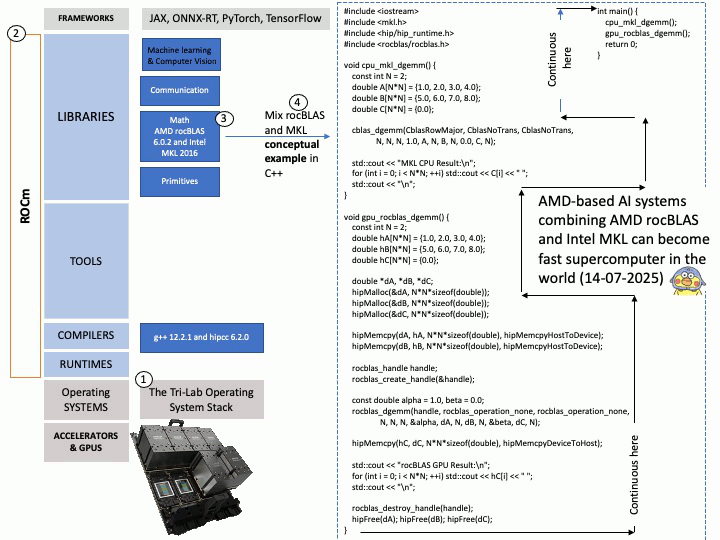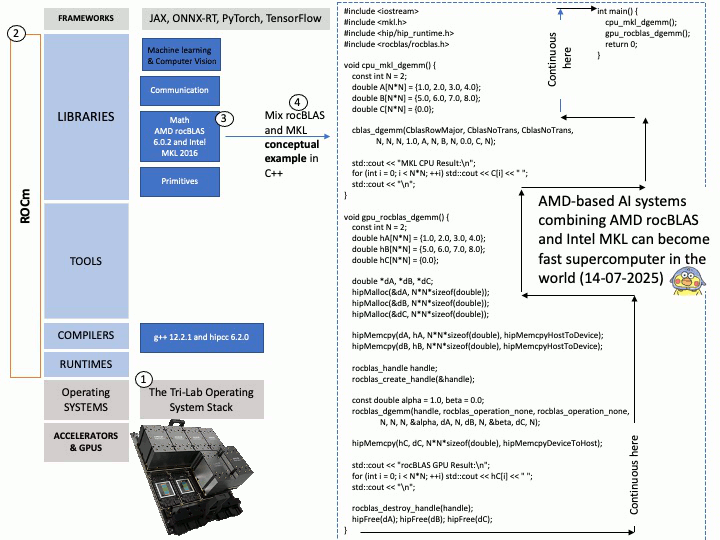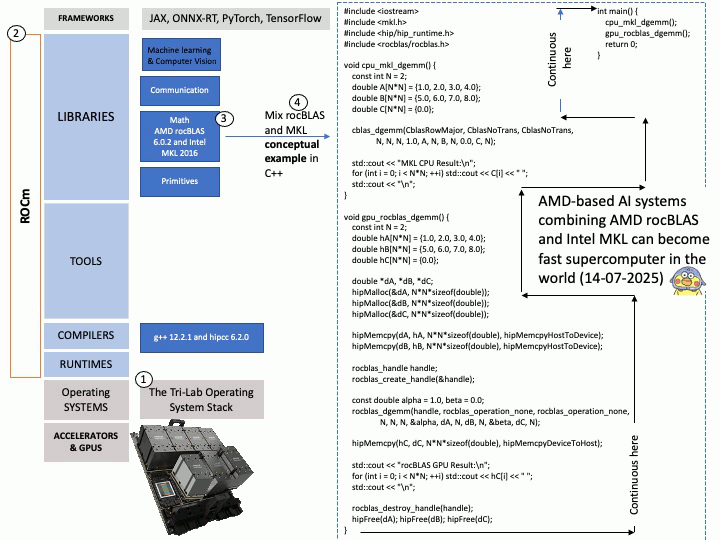
Preface: Arm Development Studio (Arm DS) is a suite of software tools designed for developing and debugging software for Arm-based SoCs (Systems on Chip). Thus, Arm DS optimizing software for Arm-based hardware, primarily in embedded systems and IoT devices. These tools help developers write, compile, and debug code for various Arm processors, including those found in SoCs. Applications built with Arm DS can be deployed to various targets, including microcontrollers, embedded Linux systems, and even Android devices.
Background: Arm Development Studio is available for both Windows and Linux operating systems. Specifically, it supports 64-bit x86 host platforms for both Windows 10 and Linux distributions like Red Hat Enterprise Linux 7 and Ubuntu Desktop Editions 18.04 LTS and 20.04 LTS.
Redistributable Packages: For distributing applications built with Arm Development Studio, developers might need to include redistributable packages like those related to the Visual C++ runtime libraries, which are also provided as [.]dll files.
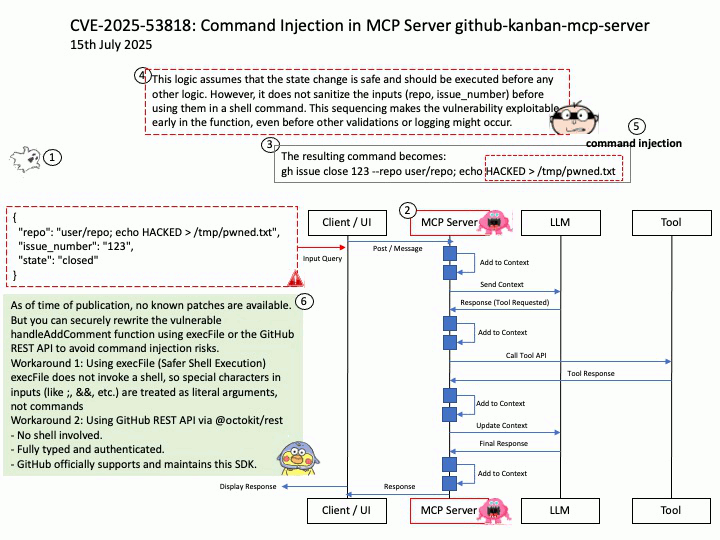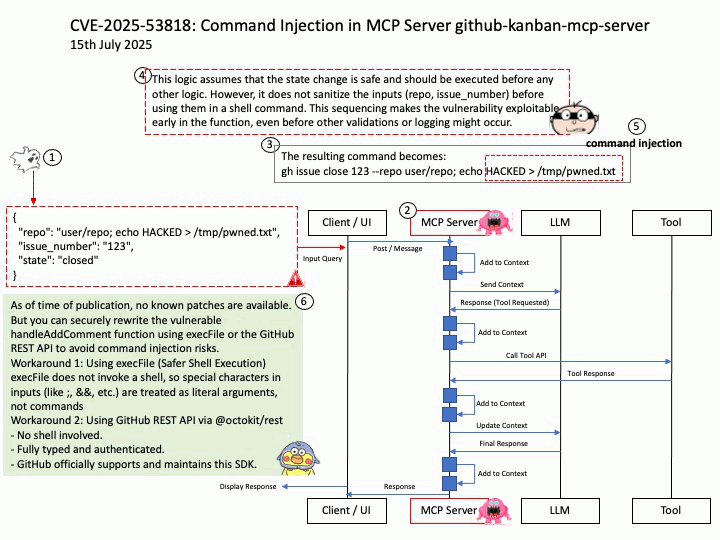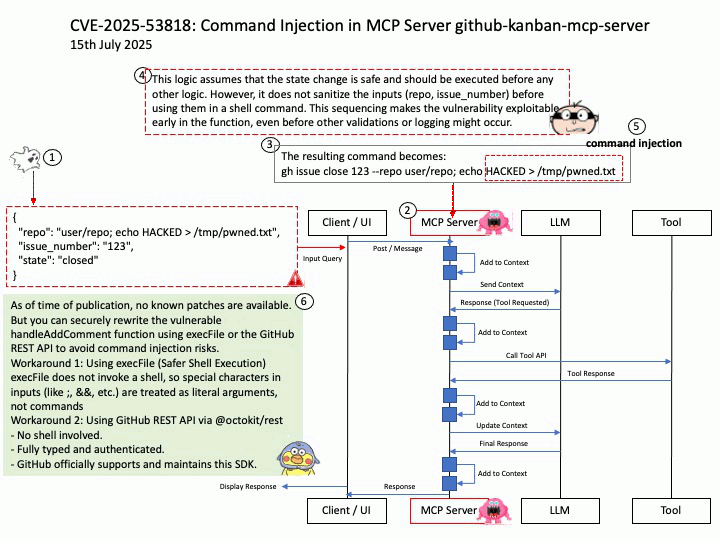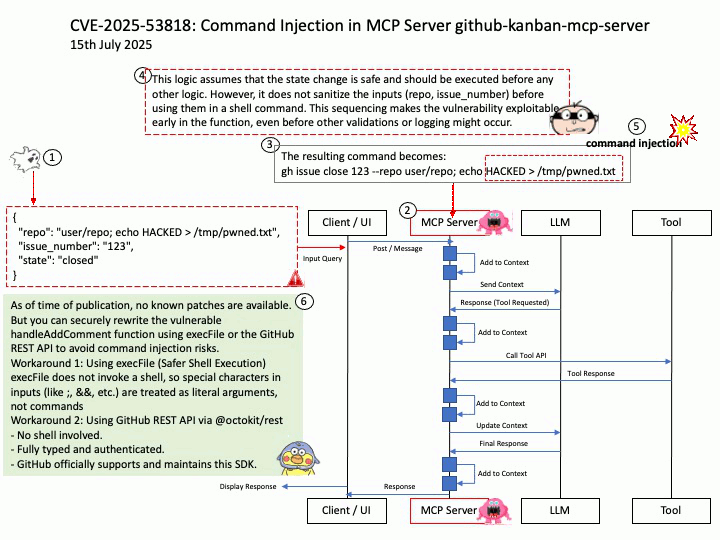
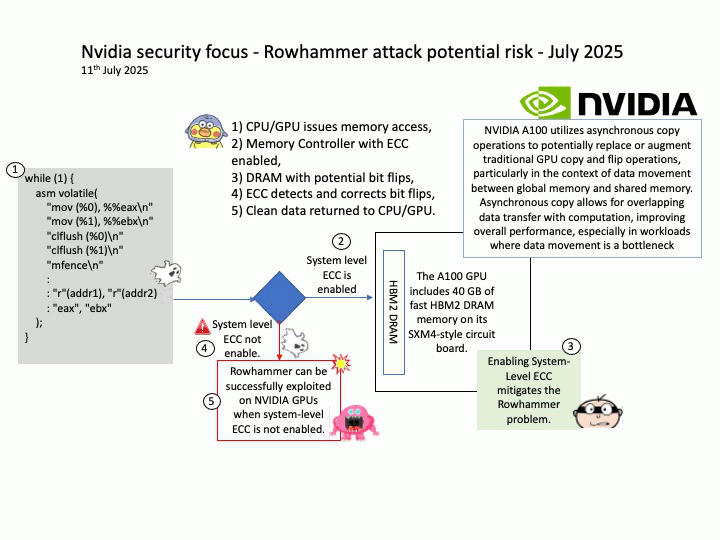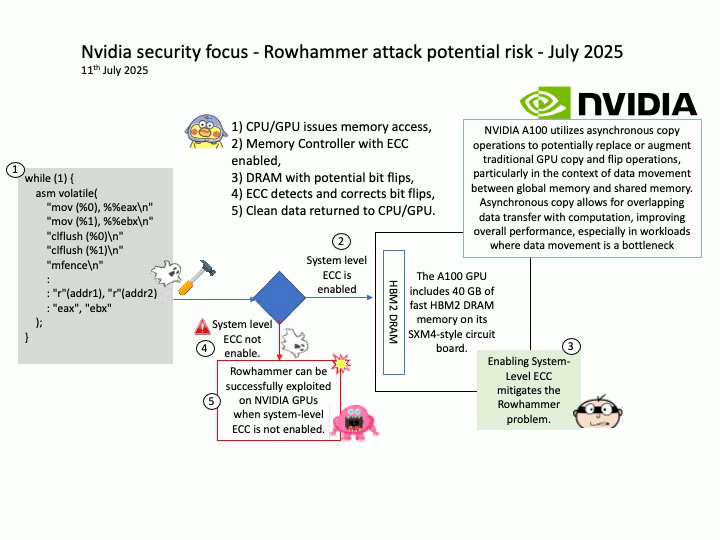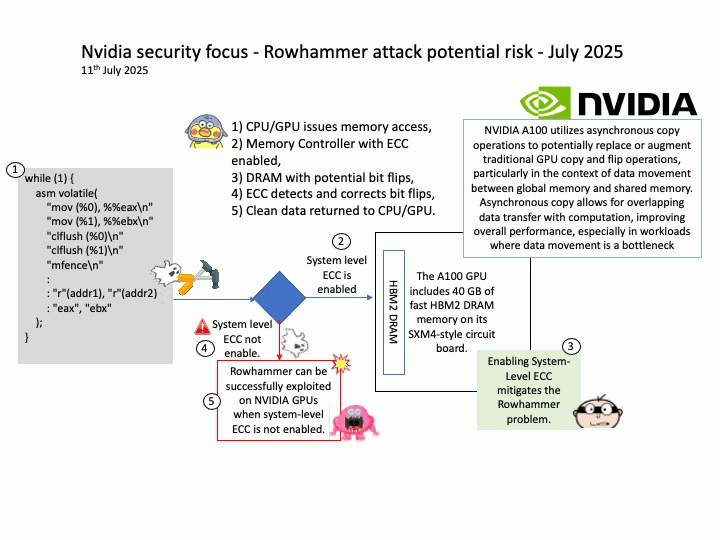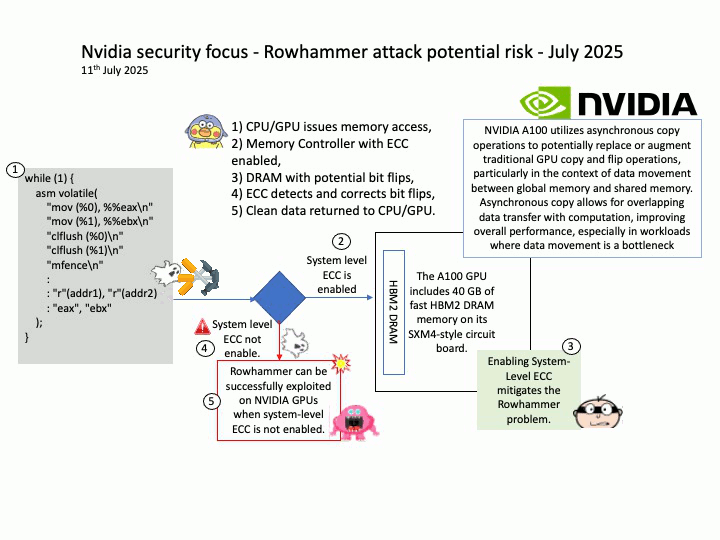
Vulnerability details: CVE-2025-32702: Improper neutralization of special elements used in a command (‘command injection’) in Visual Studio allows an unauthorized attacker to execute code locally.
Official announcement: Please refer to the URL for details https://nvd.nist.gov/vuln/detail/CVE-2025-32702