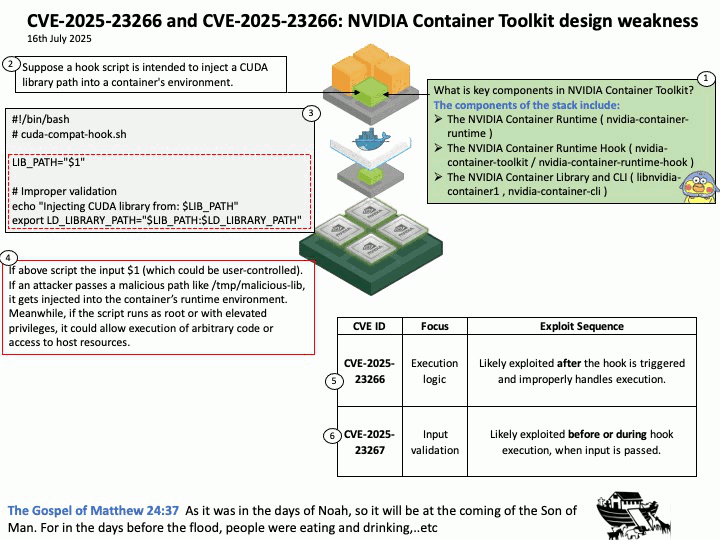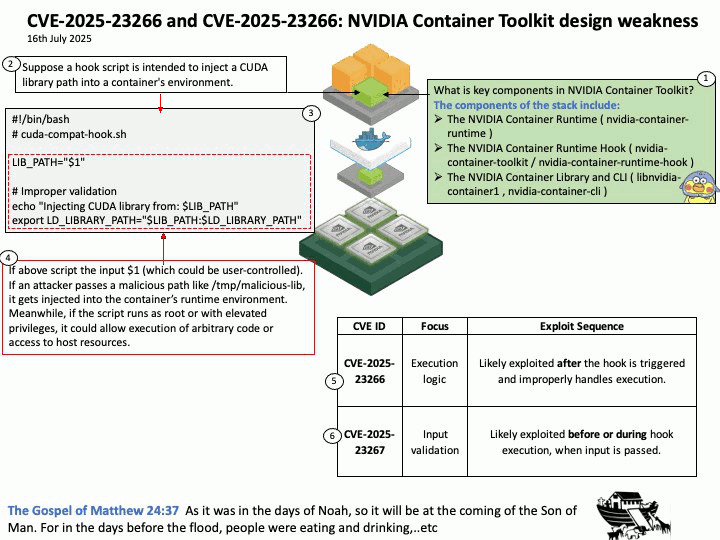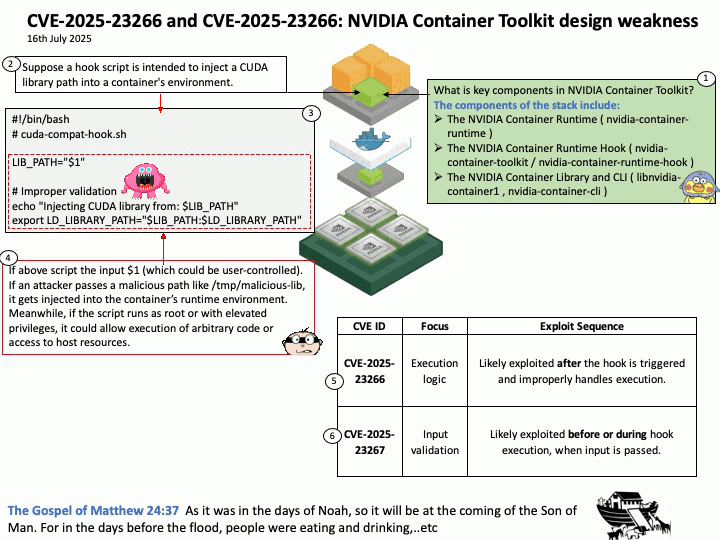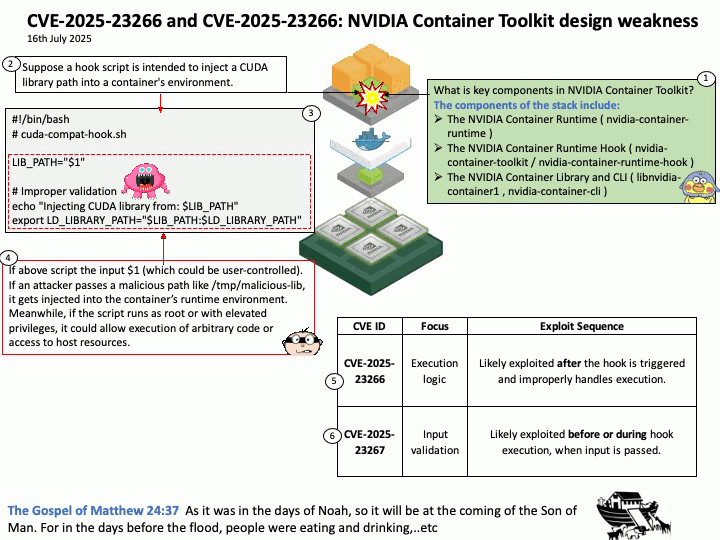
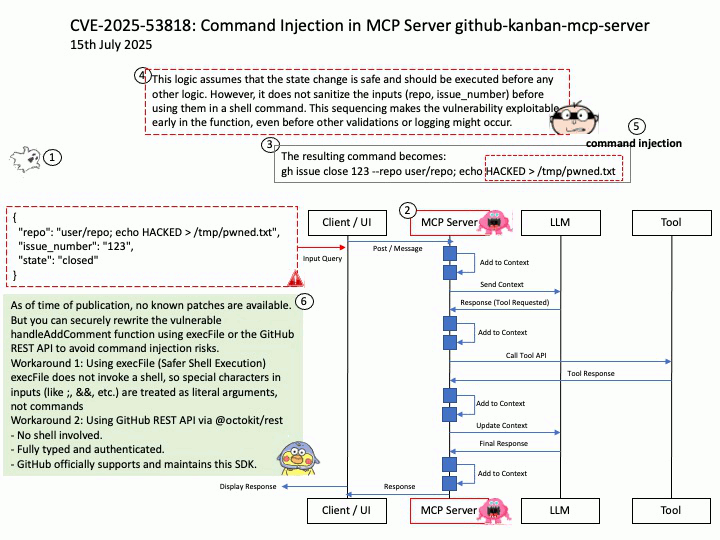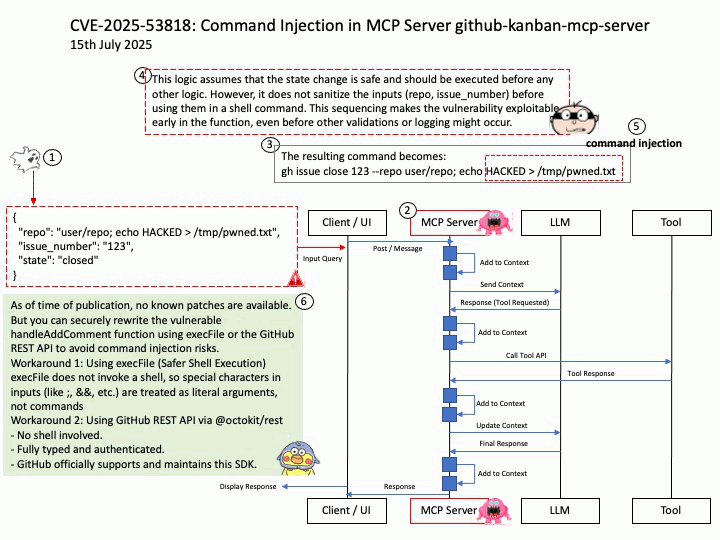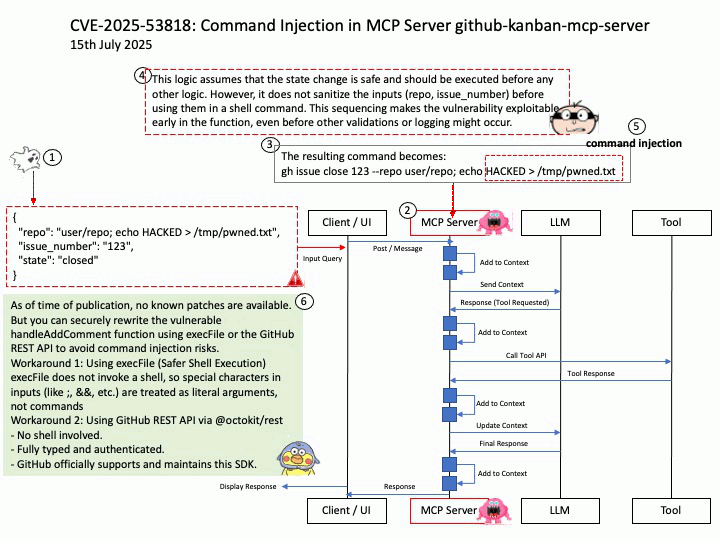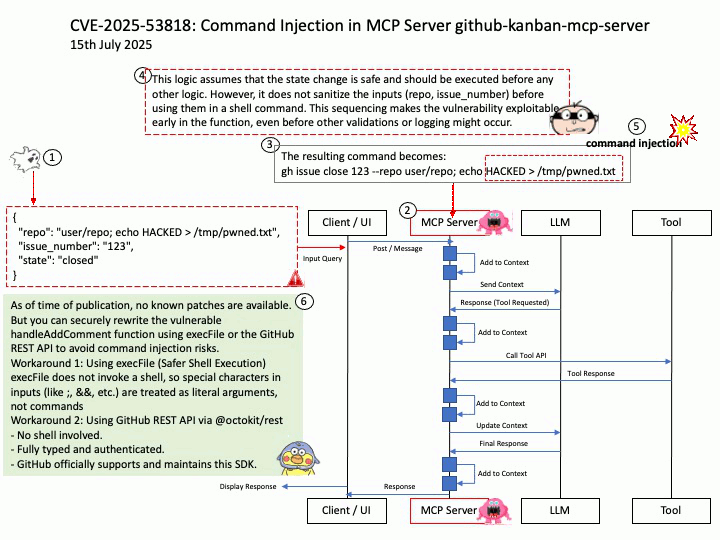
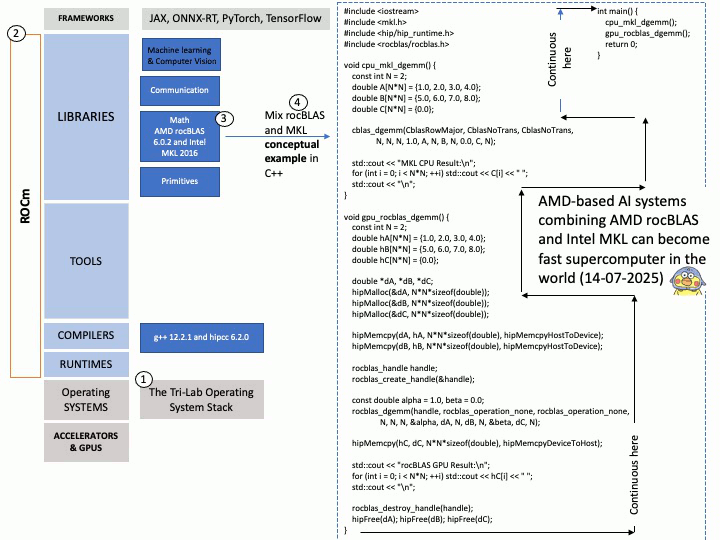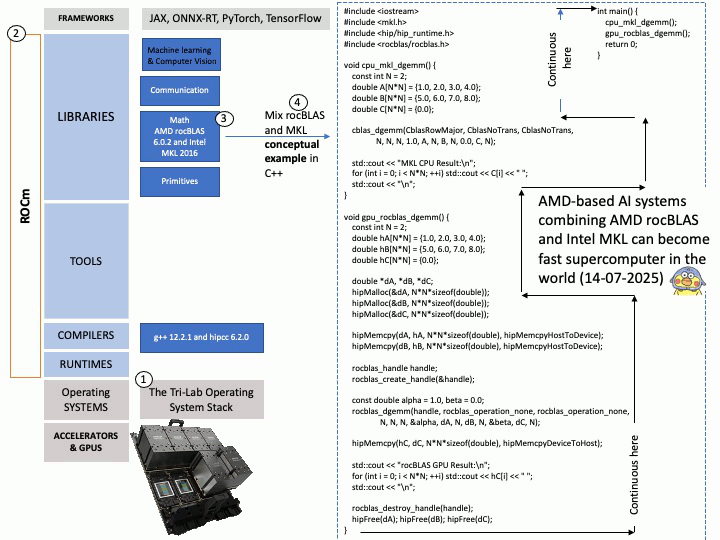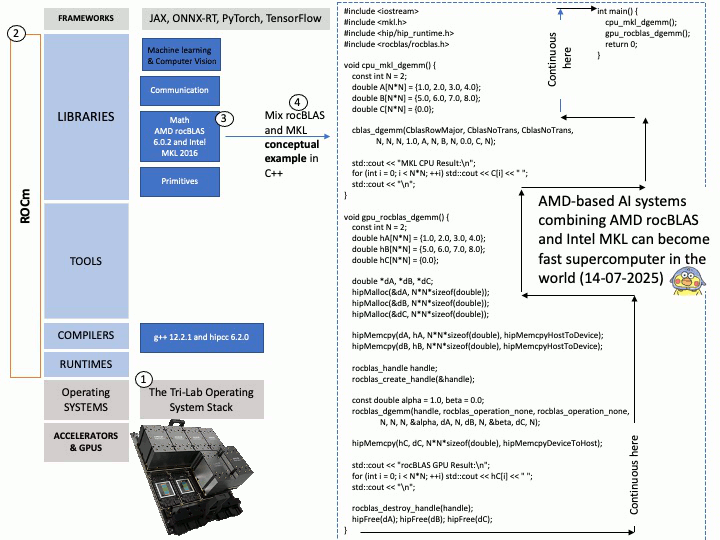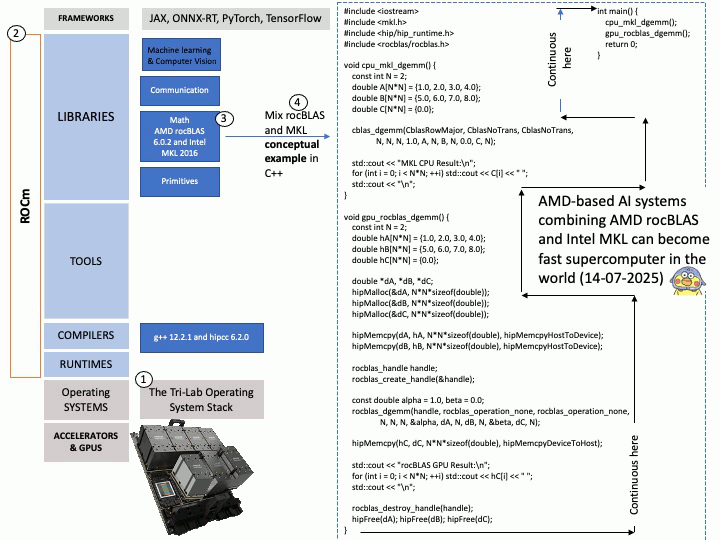
Preface: The NVIDIA Triton Inference Server API supports both HTTP/REST and GRPC protocols. These protocols allow clients to communicate with the Triton server for various tasks such as model inferencing, checking server and model health, and managing model metadata and statistics.
Background: NVIDIA Triton™ Inference Server, part of the NVIDIA AI platform and available with NVIDIA AI Enterprise, is open-source software that standardizes AI model deployment and execution across every workload.
The Asynchronous Server Gateway Interface (ASGI) is a calling convention for web servers to forward requests to asynchronous-capable Python frameworks, and applications. It is built as a successor to the Web Server Gateway Interface (WSGI).
NVIDIA Triton Inference Server integrates a built-in web server to expose its functionality and allow clients to interact with it. This web server is fundamental to how Triton operates and provides access to its inference capabilities on both Windows and Linux environments.
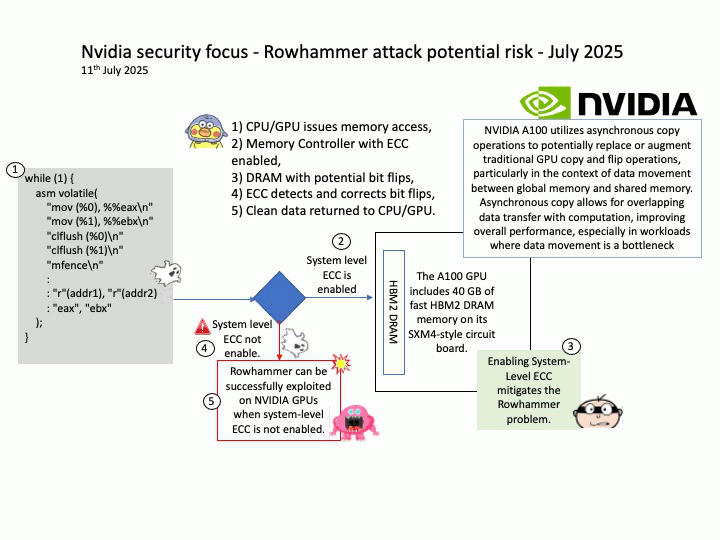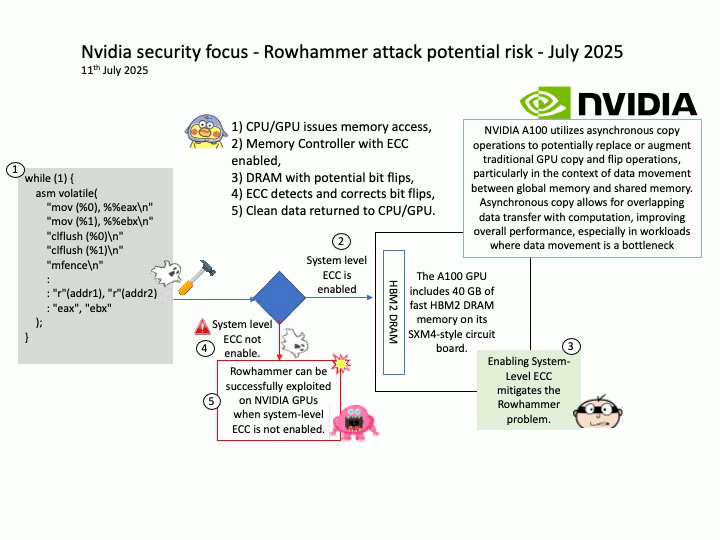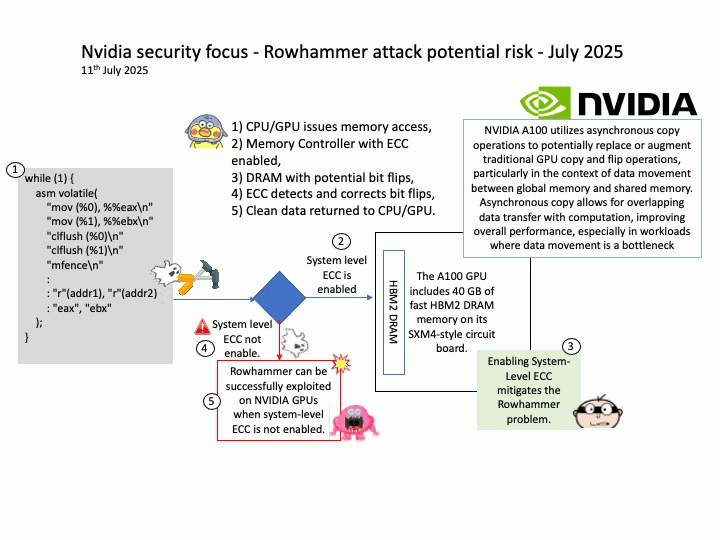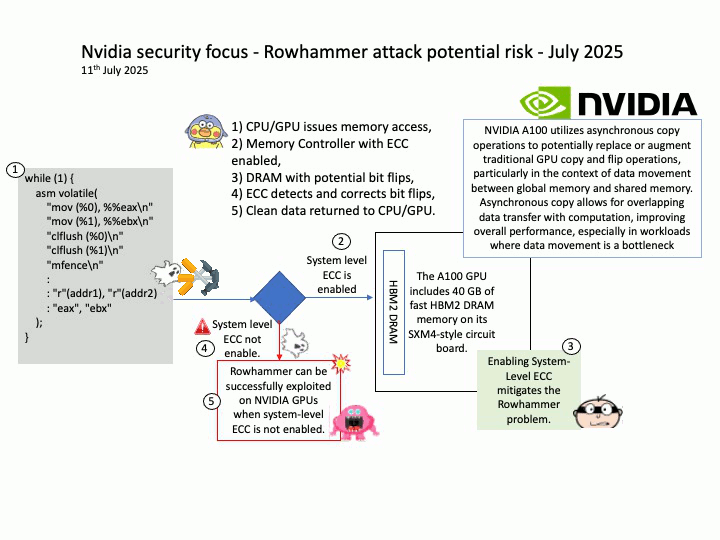
Vulnerability details: CVE-2025-23310 – NVIDIA Triton Inference Server for Windows and Linux contains a vulnerability where an attacker could cause stack buffer overflow by specially crafted inputs. A successful exploit of this vulnerability might lead to remote code execution, denial of service, information disclosure, and data tampering.
Official announcement: Please refer to the link for details –