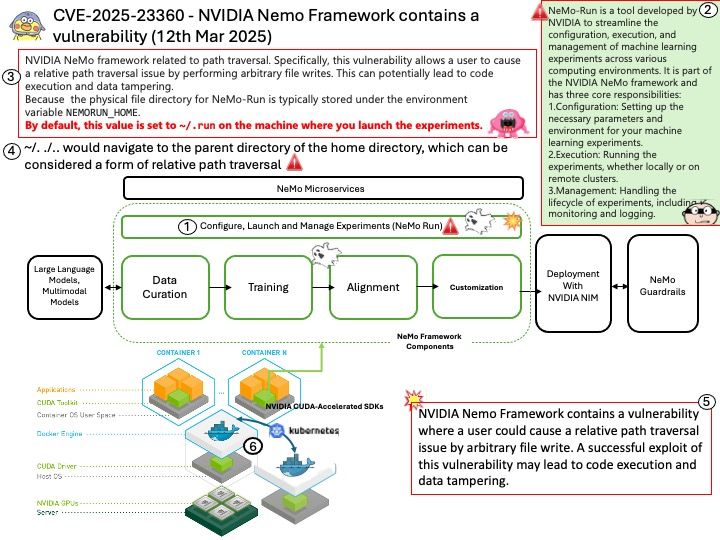
Preface: The symbol ~/. by itself is not a relative path traversal; it simply refers to the home directory of the current user. However, when combined with ./.., it can be part of a relative path traversal.
Relative path traversal involves using sequences like ../ to navigate up the directory hierarchy. For example, ~/. refers to the home directory, and ./.. moves up one directory level from the current directory. So, ~/. ./.. would navigate to the parent directory of the home directory, which can be considered a form of relative path traversal
Background: NVIDIA NeMo is an end-to-end platform designed for developing and deploying generative AI models. This includes large language models (LLMs), vision language models (VLMs), video models, and speech AI. NeMo offers tools for data curation, fine-tuning, retrieval-augmented generation (RAG), and inference, making it a comprehensive solution for creating enterprise-ready AI models. Here are some key capabilities of NeMo LLMs:
- Customization: NeMo allows you to fine-tune pre-trained models to suit specific enterprise needs. This includes adding domain-specific knowledge and skills, and continuously improving the model with reinforcement learning from human feedback (RLHF).
- Scalability: NeMo supports large-scale training and deployment across various environments, including cloud, data centers, and edge devices. This ensures high performance and flexibility for different use cases.
- Foundation Models: NeMo offers a range of pre-trained foundation models, such as GPT-8, GPT-43, and GPT-530, which can be used for tasks like text classification, summarization, creative writing, and chatbots.
- Data Curation: The platform includes tools for processing and curating large datasets, which helps improve the accuracy and relevance of the models.
- Integration: NeMo can be integrated with other NVIDIA AI tools and services, providing a comprehensive ecosystem for AI development.
Vulnerability details: NVIDIA Nemo Framework contains a vulnerability where a user could cause a relative path traversal issue by arbitrary file write. A successful exploit of this vulnerability may lead to code execution and data tampering.
Official announcement: Please see the official link for details