Preface: An NVIDIA endless “collect-export” loop refers to the standard, continuous operation of the DOCA Telemetry Service (DTS), where telemetry data is perpetually collected and then exported. While high-frequency telemetry (HFT) offers an external, triggered alternative, the standard DTS flow is designed to run indefinitely, collecting data from the Sysfs provider and potentially exporting it via Prometheus or Fluent Bit.
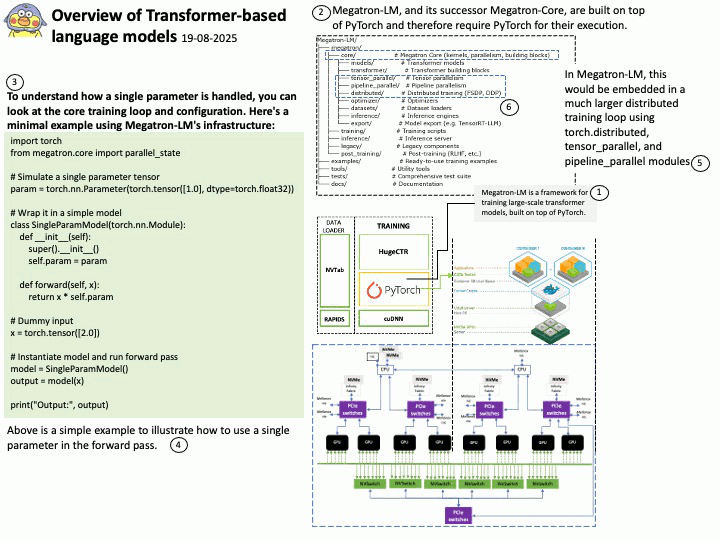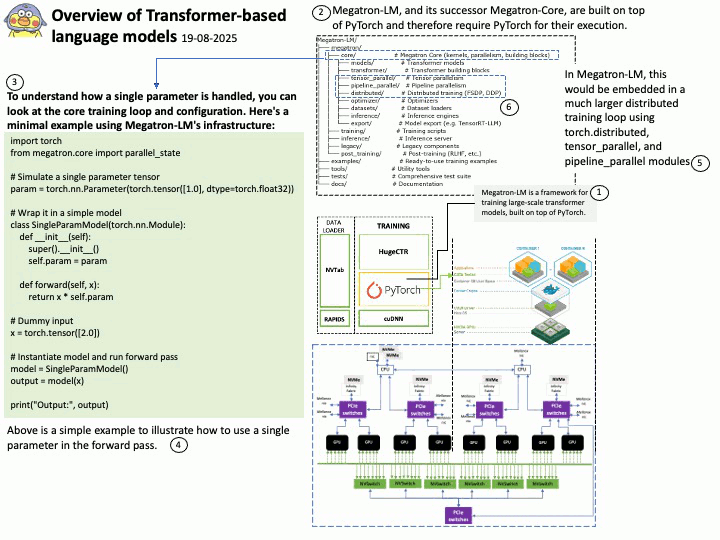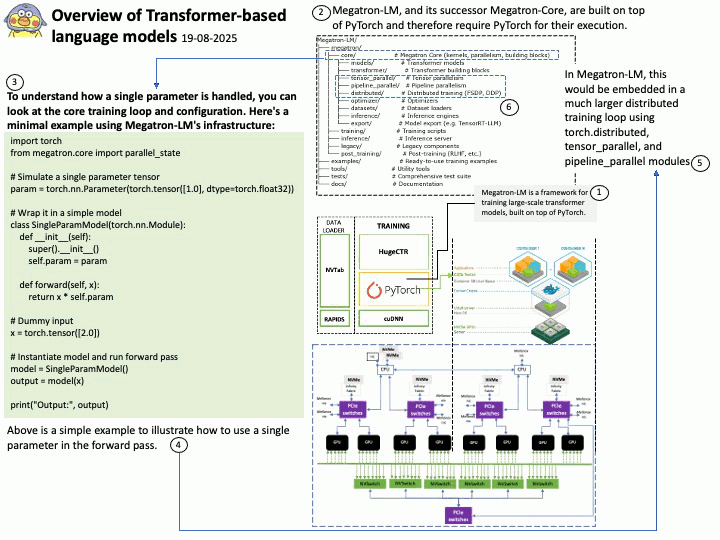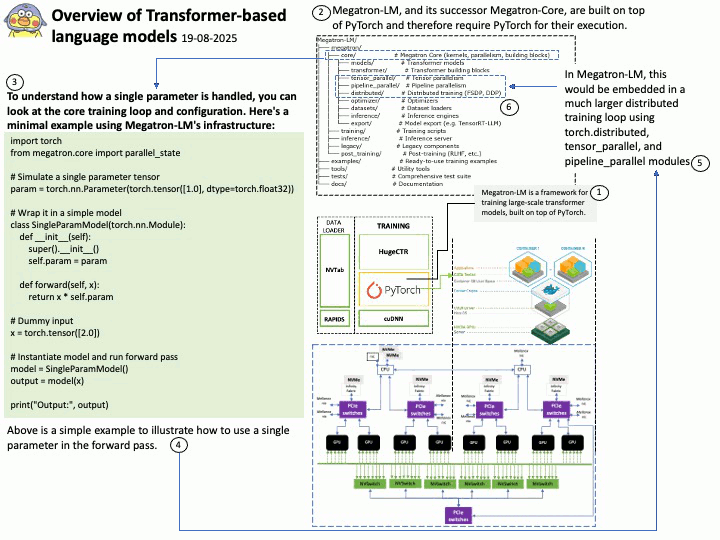
Background: CUDA (Compute Unified Device Architecture) and DOCA (Data Center Infrastructure-on-a-Chip Architecture) are both NVIDIA SDKs, but they serve distinct purposes and target different hardware.
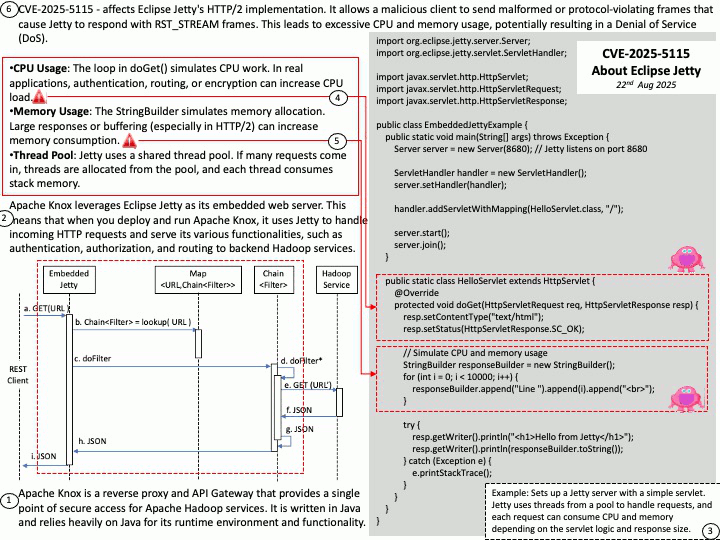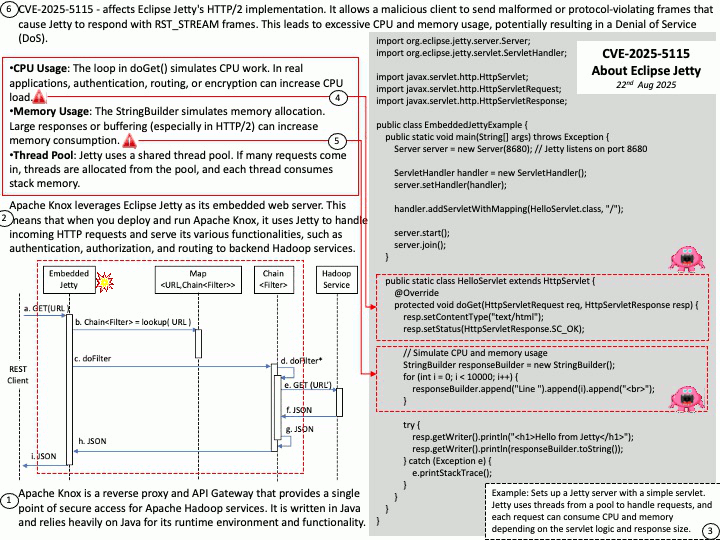
CUDA SDK: Primarily designed for general-purpose computing on NVIDIA GPUs. It enables developers to program accelerated computing applications by leveraging the parallel processing power of GPUs.
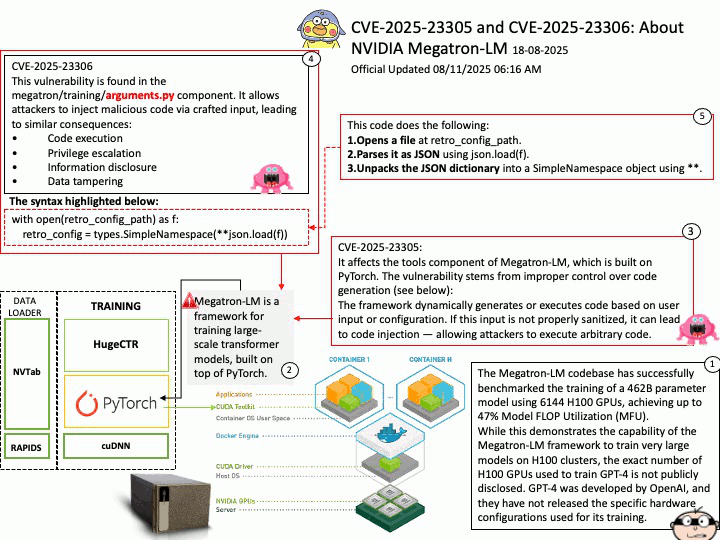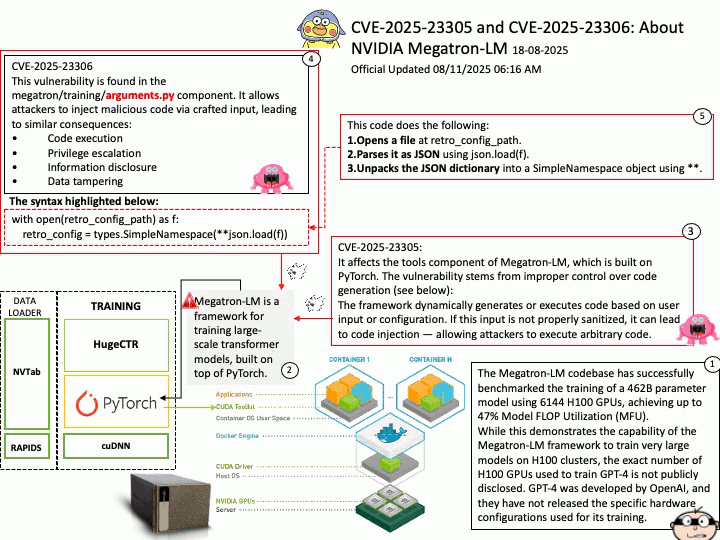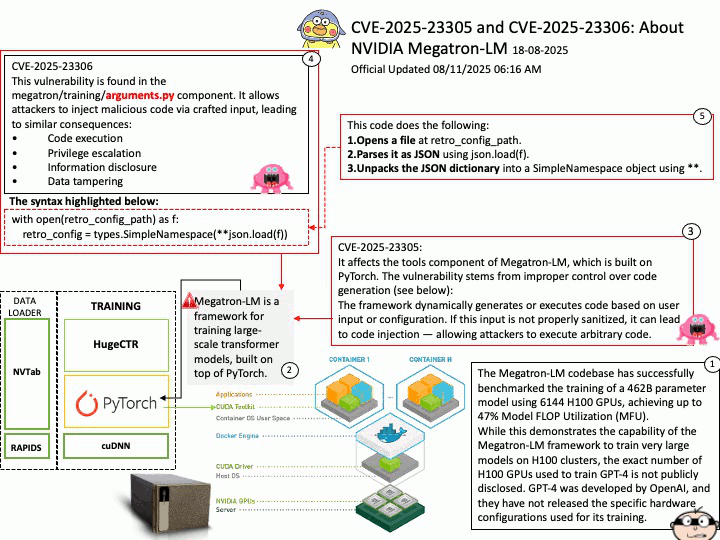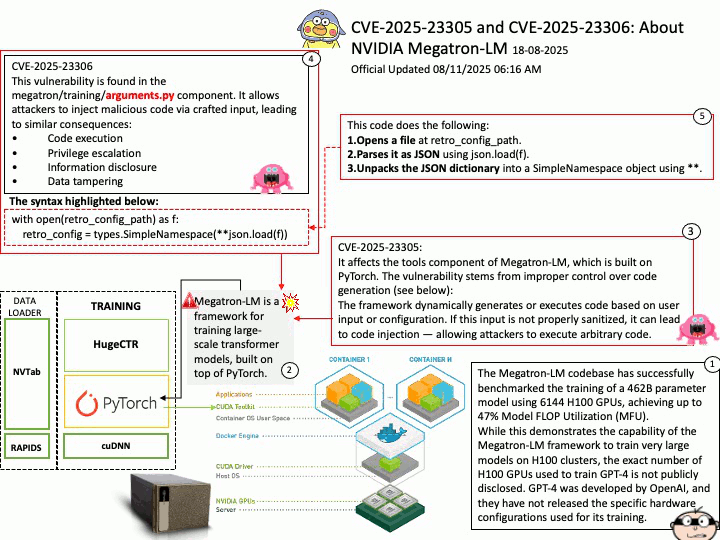
DOCA SDK: Built specifically for NVIDIA BlueField Data Processing Units (DPUs) and SuperNICs, aiming to accelerate data center infrastructure tasks. It enables offloading infrastructure-related workloads from the host CPU to the DPU.
DOCA Telemetry Service (DTS) is a DOCA Service for collecting and exporting telemetry data. It can run on hosts and BlueField, collecting data from built-in providers and external telemetry applications. The service supports various providers, including sysfs, ethtool, ifconfig, PPCC, DCGM, NVIDIA SMI, and more.
Ref: The binary data can be read using the /opt/mellanox/collectx/bin/clx_read app, packaged in collectx-clxapidev , a DOCA dependency package.
Vulnerability details:
CVE-2025-23257: NVIDIA DOCA contains a vulnerability in the collectx-clxapidev Debian package that could allow an actor with low privileges to escalate privileges. A successful exploit of this vulnerability might lead to escalation of privileges.
CVE-2025-23258: NVIDIA DOCA contains a vulnerability in the collectx-dpeserver Debian package for arm64 that could allow an attacker with low privileges to escalate privileges. A successful exploit of this vulnerability might lead to escalation of privileges.
Official announcement: Please see the link for details –