Technical Highlights: Megatron-LM codebase efficiently trains models from 2 billion to 462 billion parameters across thousands of GPUs, achieving up to 47% Model FLOP Utilization (MFU) on H100 clusters. The Megatron-LM codebase has successfully benchmarked the training of a 462B parameter model using 6144 H100 GPUs, achieving up to 47% Model FLOP Utilization (MFU).
GPT-4, the latest iteration in OpenAI’s Generative Pre-trained Transformer series, significantly scales up the parameter count compared to its predecessors. While GPT-2 had 1.5 billion parameters and GPT-3 boasted 175 billion, GPT-4 is estimated to have a staggering 1.76 trillion parameters.
Parameters in Artificial Intelligence:
Parameters in AI are the variables that the model learns during training. They are the internal variables that the model uses to make predictions or decisions. In a neural network, the parameters include the weights and biases of the neurons. Parameters are used in AI to determine the output of the model for a given input. During training, the model adjusts its parameters to minimize the difference between its predictions and the actual values. This is typically done using an optimization algorithm, such as gradient descent. Gradient descent is a fundamental optimization algorithm in artificial intelligence, particularly in machine learning and deep learning. It’s used to minimize a function, often the cost function of a model, by iteratively adjusting the model’s parameters in the direction of the steepest descent.
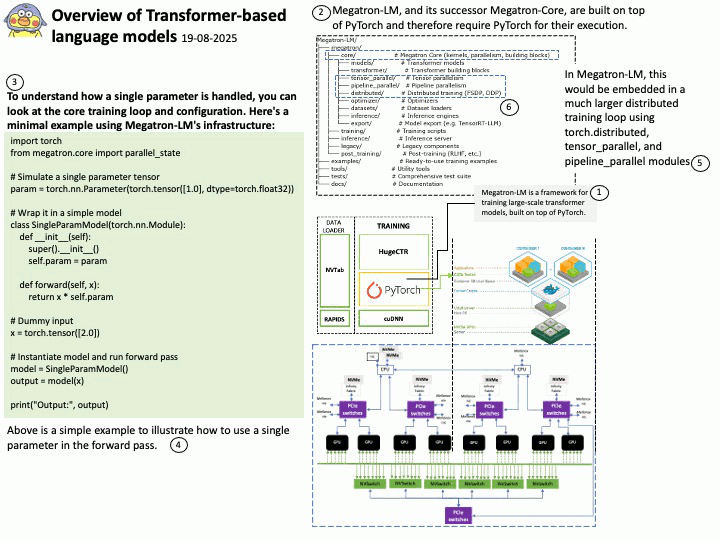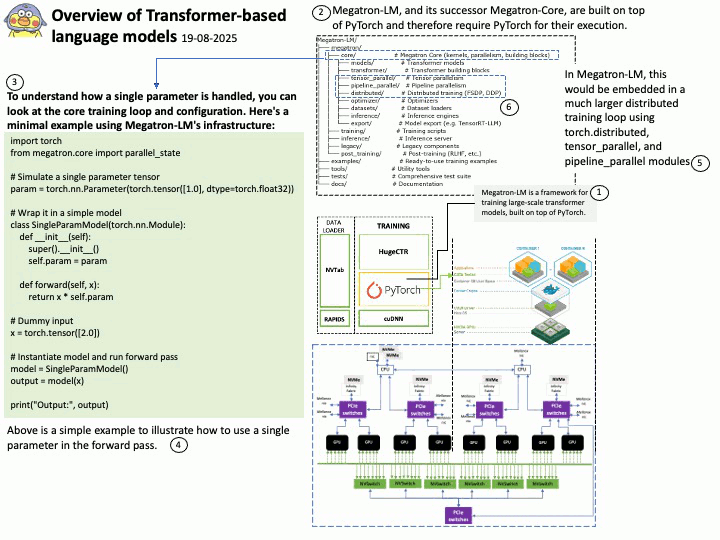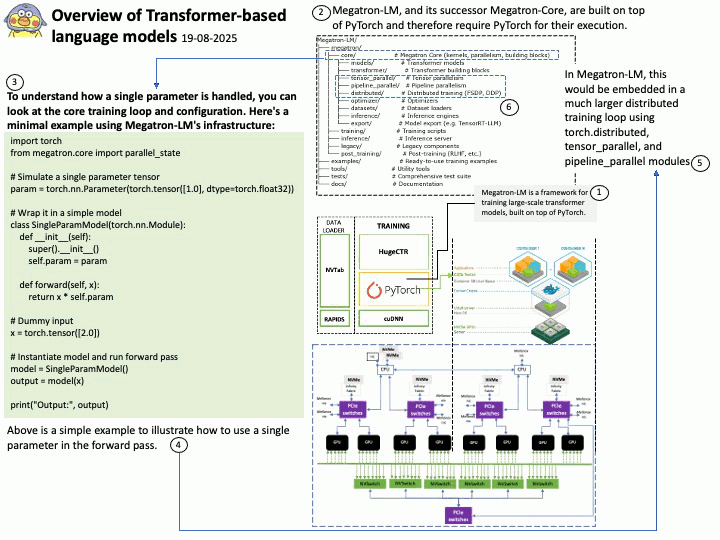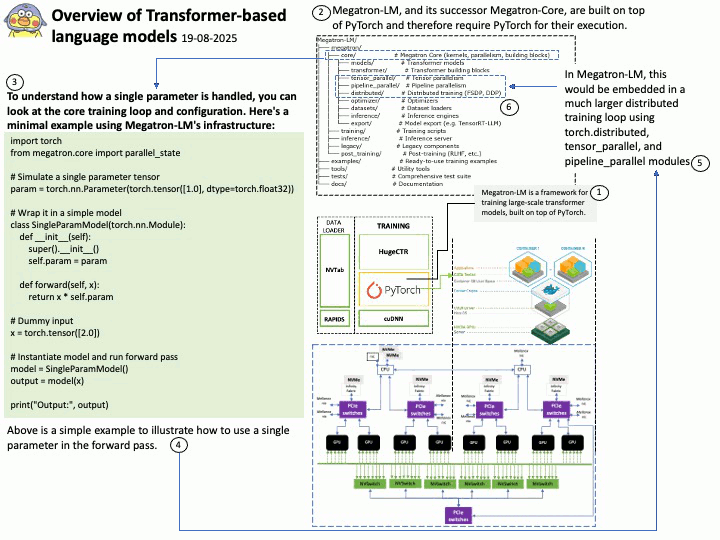
About Megatron-LM: The Megatron-LM codebase, developed by NVIDIA, is widely used for training large parameter models, particularly Large Language Models (LLMs), due to its specialized features and optimizations designed for large-scale distributed training. Megatron-LM is a GPU-optimized framework developed by NVIDIA for training transformer models at scale. It supports models ranging from a few billion to hundreds of billions of parameters.
Outlines the core techniques:
- Intra-layer model parallelism
- Pipeline parallelism
- Tensor parallelism
- Efficient communication primitives using NCCL
- Mixed precision training (FP16/BF16)
Ref: NVIDIA Collective Communications Library (NCCL), is a library developed by NVIDIA that provides optimized routines for multi-GPU and multi-node communication. It’s designed to accelerate collective communication patterns, like all-reduce, broadcast, reduce, and all-gather, which are crucial for deep learning frameworks and other parallel computing applications using NVIDIA GPUs.
Ref: FP16 and BF16 are both 16-bit floating-point formats used in AI training to improve performance and efficiency, but they differ in their dynamic range and precision. FP16, also known as half precision, offers higher precision for smaller values but has a limited range. BF16, or Brain Floating Point, has a wider dynamic range, making it more suitable for large-scale models where numerical stability is crucial, even at the cost of some precision.
Official details: For details, please refer to the link – https://github.com/NVIDIA/Megatron-LM