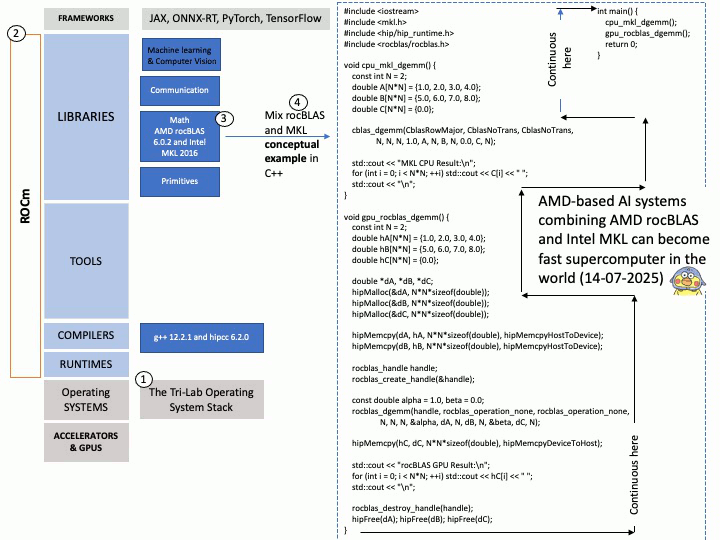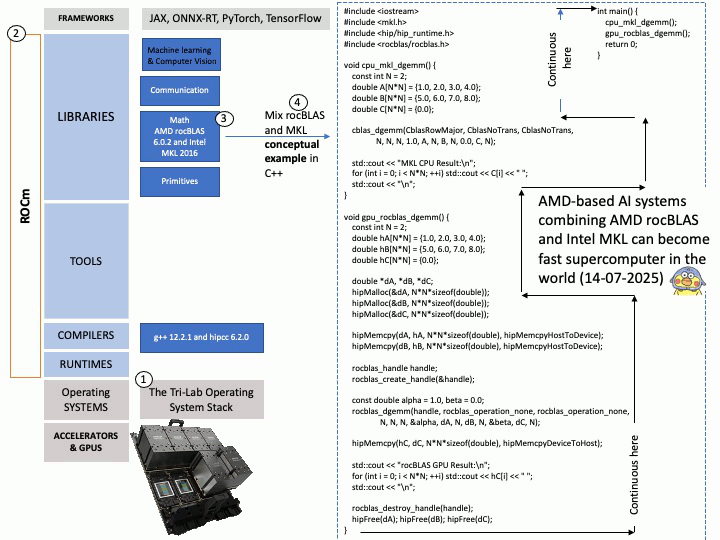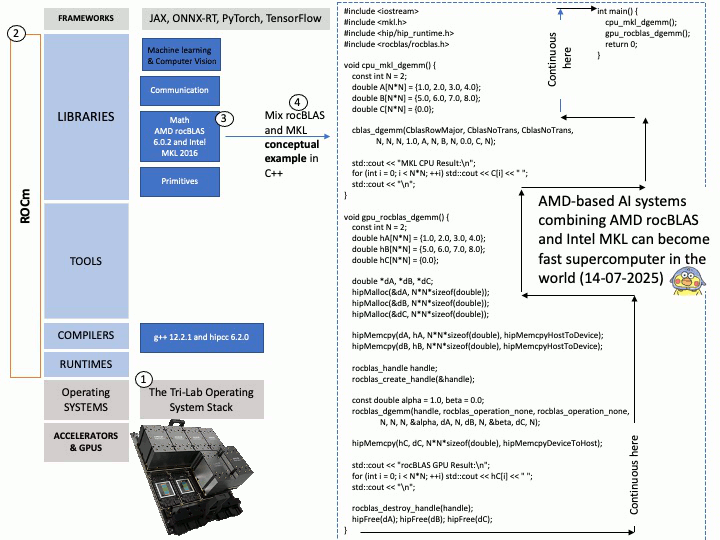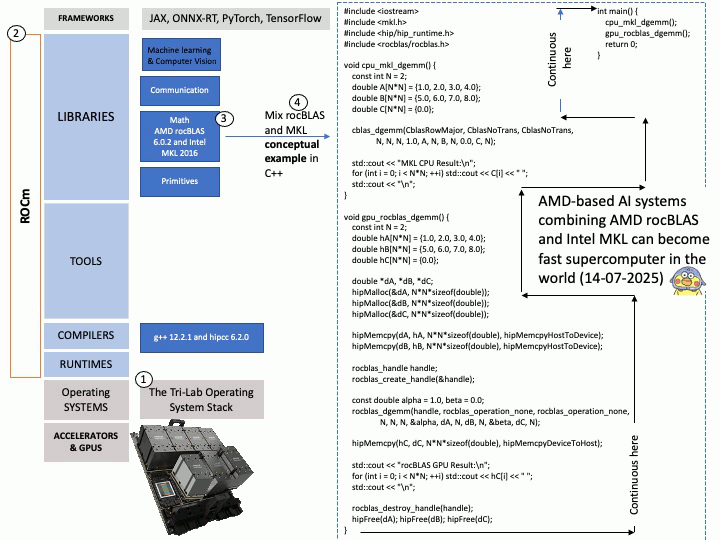
Preface: Mellanox OpenFabrics Enterprise Distribution for Linux (MLNX_OFED) is a software stack developed by NVIDIA (formerly Mellanox) that provides a tested and packaged version of the OpenFabrics Enterprise Distribution (OFED) for Mellanox network adapters. It enables high-performance networking capabilities, including RDMA and kernel bypass, for InfiniBand and Ethernet (RoCE) technologies.
Background: NVIDIA introduced DOCA-OFED in the DOCA-Host package. DOCA-Host is a unified package for host servers that includes all the basic components of DOCA and MLNX_OFED. MLNX_OFED is a single Virtual Protocol Interconnect (VPI) software stack that operates across all NVIDIA network adapter solutions.
Nvidia has also developed the Computing Unified Device Architecture (CUDA) and Data Center Infrastructure Single-Chip Architecture (DOCA) for CPU and GPU, CPU and DPU.
During the GTC conference in the fall of 2020, the SmartNIC technology they acquired after acquiring network equipment manufacturer Mellanox was officially unveiled under the name of DPU. Mellanox’s BlueField product line is considered a DPU (Data Processing Unit) because it’s designed to offload and accelerate data-centric tasks, such as networking, storage, and security, from the CPU. Essentially, DPUs like BlueField act as a specialized co-processor, handling tasks that would otherwise consume valuable CPU resources, improving overall system performance and efficiency. NVIDIA BlueField DPUs (Data Processing Units) are designed as System on a Chip (SoC) devices.
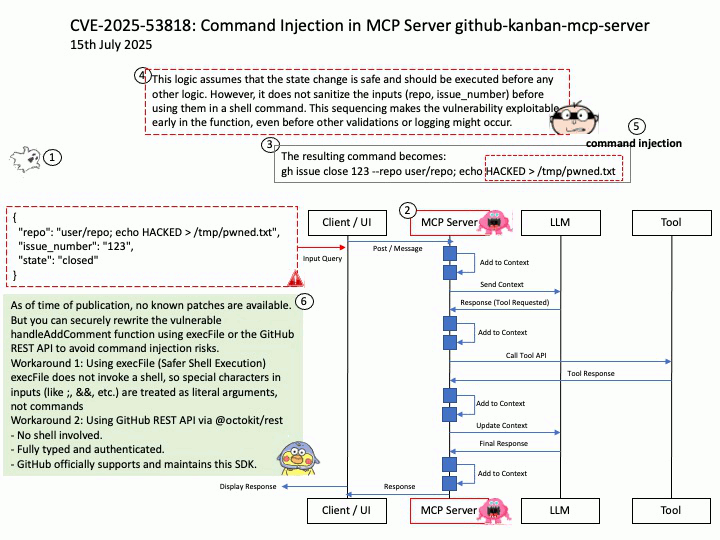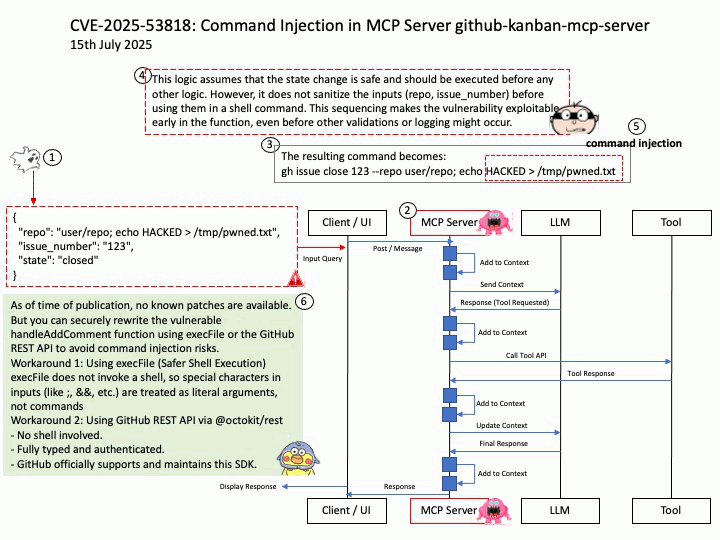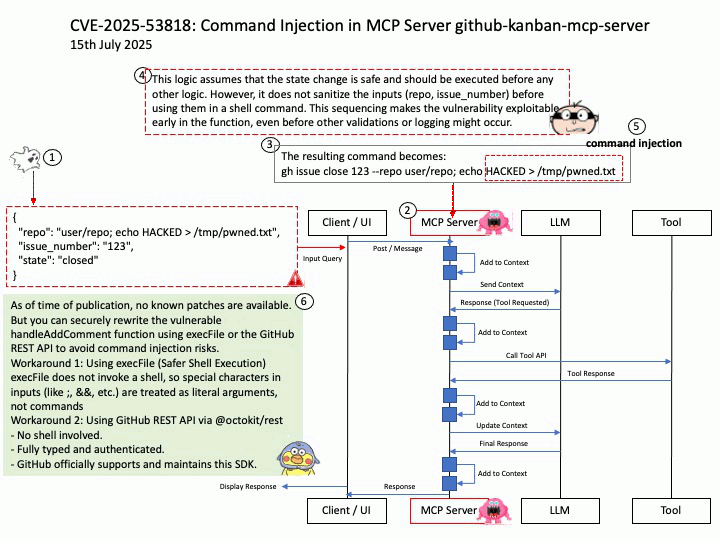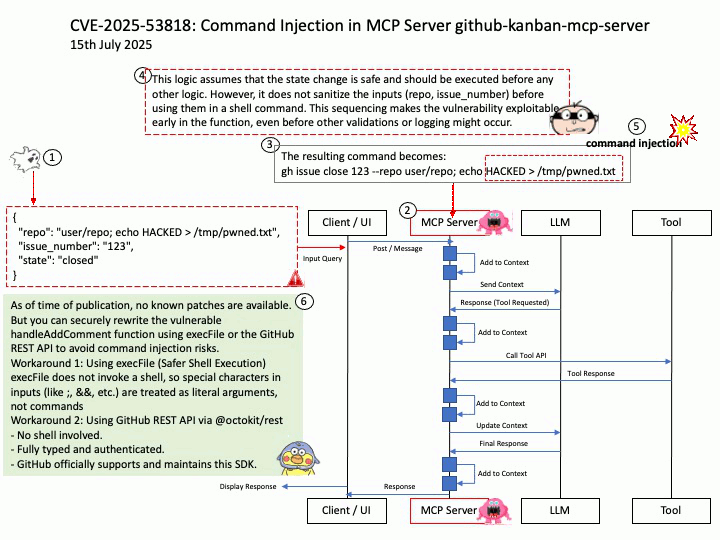
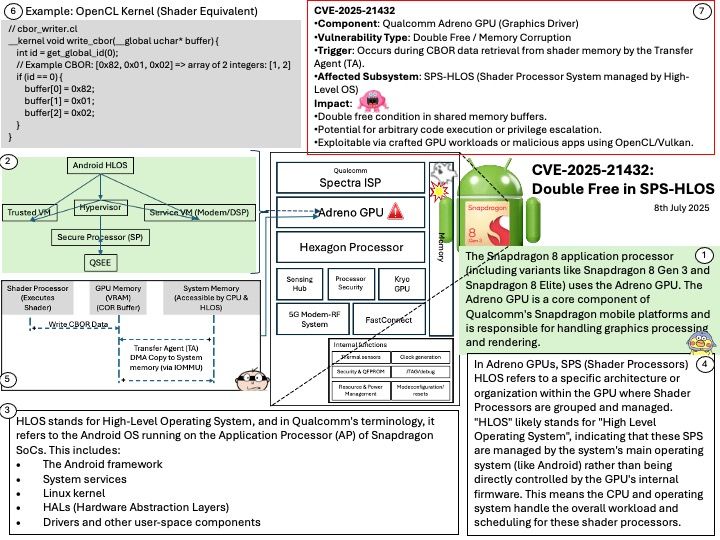
Vulnerability details: NVIDIA DOCA-Host and Mellanox OFED contain a vulnerability in the VGT+ feature, where an attacker on a VM might cause escalation of privileges and denial of service on the VLAN.
Official announcement: Please refer to url for details – https://nvidia.custhelp.com/app/answers/detail/a_id/5654