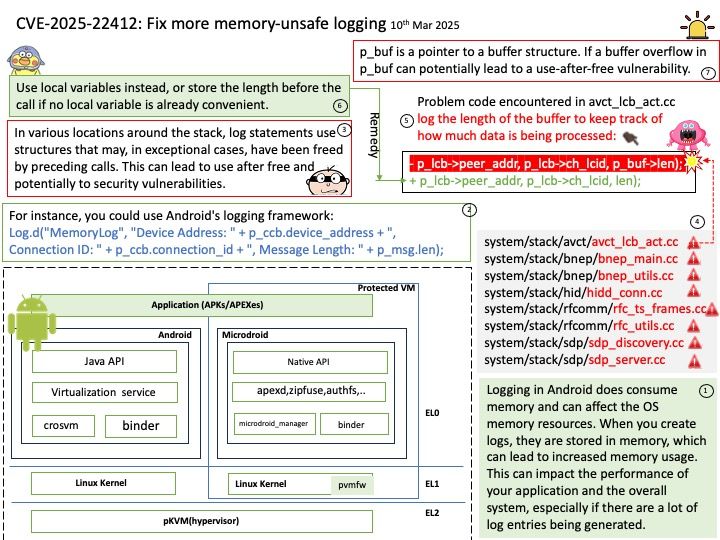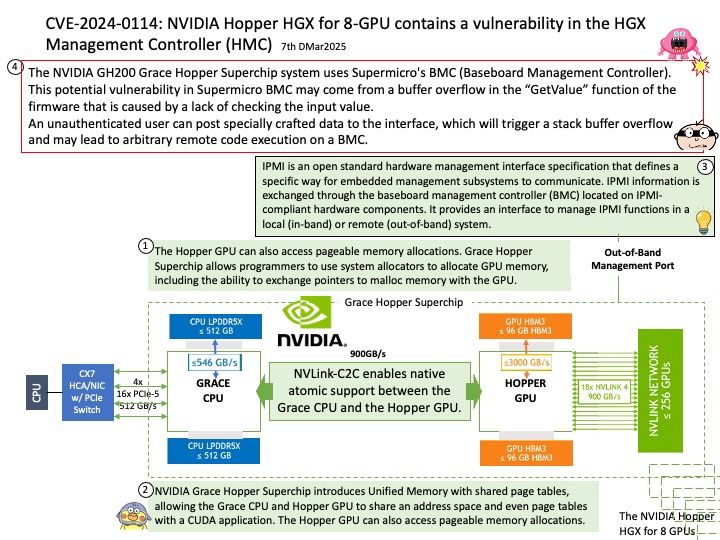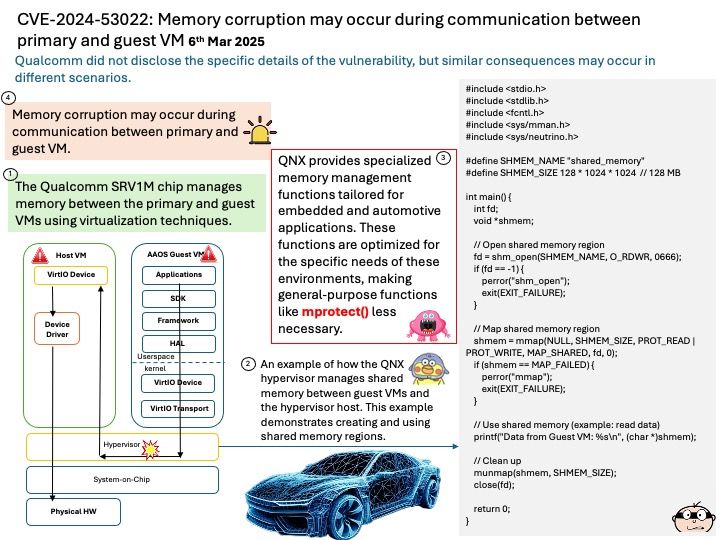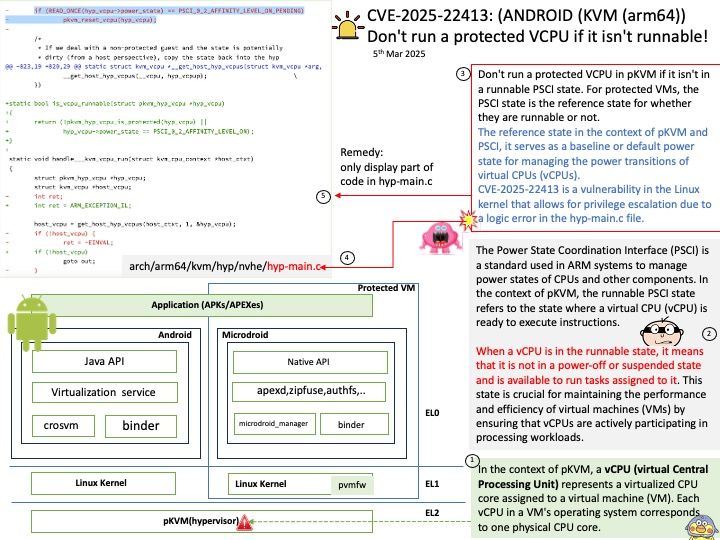
Initial release: August 8, 2023
Last updated: 14 Mar 2025
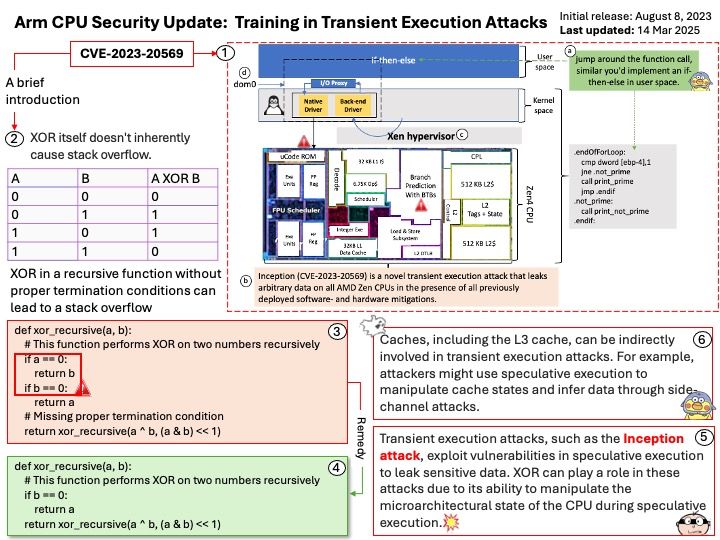
Preface: AMD’s Zen3 and Zen4 architectures are not directly related to ARM design, as they are based on AMD’s own x86-64 architecture. ARM is concerned about Training in Transient Execution (TTE) attacks because these attacks exploit vulnerabilities in speculative execution, which can affect ARM processors just as they do other architectures like x86.
Background: There are 2 phenomena that enable an unprivileged attacker to leak arbitrary information on AMD Zen3 and Zen4 CPU products.
- Phantom speculation – Trigger misprediction without any branch at the source of the misprediction.
- Training in Transient Execution – Potential manipulate future mispredictions through a previous misprediction that attacker trigger.
Here are some key reasons why ARM is worried about TTE attacks:
Microarchitectural Manipulation: TTE attacks involve manipulating microarchitectural buffers, such as the branch target buffer (BTB) and return stack buffer (RSB), during speculative execution. This manipulation can lead to mispredictions and create transient windows where sensitive data can be accessed.
Cross-Architecture Concerns: While ARM processors have different microarchitectural designs compared to x86 processors, the fundamental principles of speculative execution and transient execution attacks apply across architectures. This means ARM needs to address these vulnerabilities to ensure the security of their processors.
Security Implications: Successful TTE attacks can bypass existing security mitigations and leak sensitive information, posing a significant threat to the security of ARM-based systems.
Official announcement: For details, please refer to the link – https://developer.arm.com/documentation/110363/1-0/?lang=en